
The corporate data center is undergoing a major transformation the likes of which haven't been seen since Intel-based servers started replacing mainframes decades ago. It isn't just the server platform: the entire infrastructure from top to bottom is seeing major changes as applications migrate to private and public clouds, networks get faster, and virtualization becomes the norm.
All of this means tomorrow's data center is going to look very different from today's. Processors, systems, and storage are getting better integrated, more virtualized, and more capable at making use of greater networking and Internet bandwidth. At the heart of these changes are major advances in networking. We're going to examine six specific trends driving the evolution of the next-generation data center and discover what both IT insiders and end-user departments outside of IT need to do to prepare for these changes.
Beyond 10Gb networks
Network connections are getting faster to be sure. Today it's common to find 10-gigabit Ethernet (GbE) connections to some large servers. But even 10GbE isn't fast enough for data centers that are heavily virtualized or handling large-scale streaming audio/video applications. As your population of virtual servers increases, you need faster networks to handle the higher information loads required to operate. Starting up a new virtual server might save you from buying a physical server, but it doesn't lessen the data traffic over the network—in fact, depending on how your virtualization infrastructure works, a virtual server can impact the network far more than a physical one. And as more audio and video applications are used by ordinary enterprises in common business situations, the file sizes balloon too. This results in multi-gigabyte files that can quickly fill up your pipes—even the big 10Gb internal pipes that make up your data center's LAN.
Part of coping with all this data transfer is being smarter about identifying network bottlenecks and removing them, such as immature network interface card drivers that slow down server throughput. Bad or sloppy routing paths can introduce network delays too. Typically, both bad drivers and bad routes haven't been carefully previously examined because they were sufficient to handle less demanding traffic patterns.
It doesn't help that more bandwidth can sometimes require new networking hardware. The vendors of these products are well prepared, and there are now numerous routers, switches, and network adapter cards that operate at 40- and even 100-gigabit Ethernet speeds. Plenty of vendors sell this gear: Dell's Force10 division, Mellanox, HP, Extreme Networks, and Brocade. It's nice to have product choices, but the adoption rate for 40GbE equipment is still rather small.
Using this fast gear is complicated by two issues. First is price: the stuff isn't cheap. Prices per 40Gb port—that is, the cost of each 40Gb port on a switch—are typically $2,500, way more than a typical 10Gb port price. Depending on the nature of your business, these higher per-port prices might be justified, but it isn't only this initial money. Most of these devices also require new kinds of wiring connectors that will make implementation of 40GbE difficult, and a smart CIO will keep total cost of ownership in mind when looking to expand beyond 10Gb.

Various layouts of the 40GbE QSFP connectors and other specifics.
As Ethernet has attained faster and faster speeds, the cable plan to run these faster networks has slowly evolved. The old RJ45 category 5 or 6 copper wiring and fiber connectors won't work with 40GbE. New connections using the Quad Small Form-factor Pluggable or QSFP standard will be required. Cables with QSFP connectors can't be "field terminated," meaning IT personnel or cable installers can't cut orange or aqua fiber to length and attach SC or LC heads themselves. Data centers will need to figure out their cabling lengths and pre-order custom cables that are manufactured with the connectors already attached ahead of time. This is potentially a big barrier for data centers used to working primarily with copper cables, and it also means any current investment in your fiber cabling likely won't cut it for these higher-speed networks of the future either.
Still, as IT managers get more of an understanding of QSFP, we can expect to see more 40 and 100 gigabit Ethernet network legs in the future, even if the runs are just short ones that go from one rack to another inside the data center itself. These are called "top of rack" switches. They link a central switch or set of switches over a high-speed connection to the servers in that rack with slower connections. A typical configuration for the future might be one or ten gigabit connections from individual servers within one rack to a switch within that rack, and then 40GbE uplink from that switch back to larger edge or core network switches. And as these faster networks are deployed, expect to see major upgrades in network management, firewalls, and other applications to handle the higher data throughput.
The rack as a data center microcosm
In the old days when x86 servers were first coming into the data center, you'd typically see information systems organized into a three-tier structure: desktops running the user interface or presentation software, a middle tier containing the logic and processing code, and the data tier contained inside the servers and databases. Those simple days are long gone.
Still living on from that time, though, are data centers that have separate racks, staffs, and management tools for servers, for storage, for routers, and for other networking infrastructure. That worked well when the applications were relatively separate and didn't rely on each other, but that doesn't work today when applications have more layers and are built to connect to each other (a Web server to a database server to a scheduling server to a cloud-based service, as a common example). And all of these pieces are running on virtualized machines anyway.
Today's equipment racks are becoming more "converged" and are handling storage, servers, and networking tasks all within a few inches of each other. The notion first started with blade technology, which puts all the essential elements of a computer on a single expansion card that can easily slip into a chassis. Blades have been around for many years, but the leap was using them along with the right management and virtualization software to bring up new instances of servers, storage, and networks. Packing many blade servers into a single large chassis also dramatically increases the density that was available in a single rack.
It is more than just bolting a bunch of things inside a rack: vendors selling these "data center in a rack" solutions are providing pre-engineering testing and integration services. They also have sample designs that can be used to specify the particular components easily that reduce cable clutter, and vendors are providing software to automate management. This arrangement improves throughput and makes the various components easier to manage. Several vendors offer this type of computing gear, including Dell's Active Infrastructure and IBM's PureSystems. It used to be necessary for different specialty departments within IT to configure different components here: one group for the servers, one for the networking infrastructure, one for storage, etc. That took a lot of coordination and effort. Now it can all be done coherently and with a single source.

Dell PowerEdge blade enclosure.
Let's look at Dell's Active Infrastructure as an example. They claim to eliminate more than 755 of the steps needed to power on a server and connect it to your network. It comes in a rack with PowerEdge Intel servers, SAN arrays from Dell's Compellent division, and blades that can be used for input/output aggregation and high-speed network connections from Dell's Force10 division. The entire package is very energy efficient and you can deploy these systems quickly. We've seen demonstrations from IBM and Dell where a complete network cluster is brought up from a cold start within an hour, and all managed from a Web browser by a system administrator who could be sitting on the opposite side of the world.
Beyond the simple SAN
As storage area networks (SANs) proliferate, they are getting more complex. SANs now use more capable storage management tools to make them more efficient and flexible. It used to be the case that SAN administration was a very specialized discipline that required arcane skills and deep knowledge of array performance tuning. That is not the case any longer, and as SAN tool sets improve, even IT generalists can bring one online.
The above data center clusters from Dell and others are just one example of how SANs have been integrated into other products. Added to these efforts, there is a growing class of management tools that can help provide a "single pane of glass" view of your entire SAN infrastructure. These also can make your collection of virtual disks more efficient.
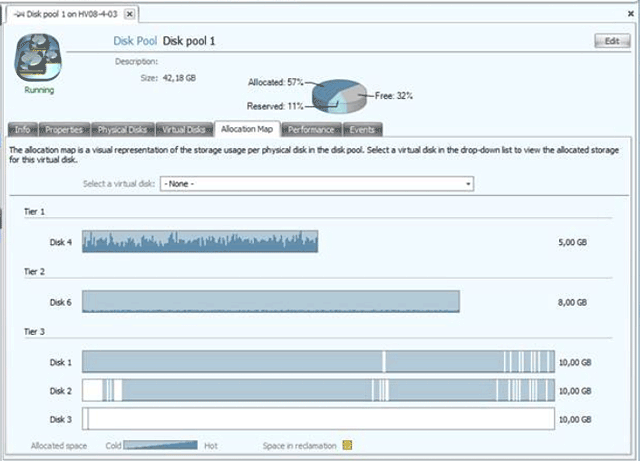
Datacore Software’s SANSymphony storage management software makes it easier to more efficiently arrange your storage capacity.
The dilemma here is you want to have enough space available to your virtual drive so that it has room to grow, so you often have to tie up space that could otherwise be used. This is where dynamic thin provisioning comes into play. Most SAN arrays have some type of thin provisioning built in and let you allocate storage without actually allocating it—a 1TB thin-provisioned volume reports itself as being 1TB in size but only actually takes up the amount of space in use by its data. In other words, a physical 1TB chunk of disk could be "thick" provisioned into a single 1TB volume or thin provisioned into maybe a dozen 1TB volumes, letting you oversubscribe the volume. Thin provisioning can play directly into your organization's storage forecasting, letting you establish maximum volume sizes early and then buying physical disk to track with the volume's growth.
Another trick many SANs can do these days is data deduplication. There are many different deduplication methods, with each vendor employing its own "secret sauce." But they all aim to reduce or eliminate the same chunks of data being stored multiple times. When employed with virtual machines, data deduplication means commonly used operating system and application files don't have to be stored in multiple virtual hard drives and can share one physical repository. Ultimately, this allows you to save on the copious space you need for these files. For example, a hundred Windows virtual machines all have essentially the same content in their "Windows" directories, their "Program Files" directories, and many other places. Deduplication ensures those common pieces of data are only stored once, freeing up tremendous amounts of space.
Software-defined networks
As enterprises invest heavily in virtualization and hybrid clouds, one element still lags: the ability to quickly provision network connections on the fly. In many cases this is due to procedural or policy issues.
Some of this lag can be removed by having a virtual network infrastructure that can be as easily provisioned as spinning up a new server or SAN. The idea behind these software-defined networks (SDNs) isn't new: indeed, the term has been around for more than a decade. A good working definition of SDN is the separation of the data and control functions of today's routers and other layer two networking infrastructure with a well-defined programming interface between the two. Most of today's routers and other networking gear mix the two functions. This makes it hard to adjust network infrastructure as we add tens or hundreds of VMs to our enterprise data centers. As each virtual server is created, you need to adjust your network addresses, firewall rules, and other networking parameters. These adjustments can take time if done manually, and they don't really scale if you are adding tens or hundreds of VMs at one time.
Automating these changes hasn't been easy. While there have been a few vendors to offer some early tools, the tools were quirky and proprietary. Many IT departments employ virtual LANs, which offer a way to segment physical networks into more manageable subsets with traffic optimization and other prioritization methods. But vLANs don't necessarily scale well either. You could be running out of head room as the amount of data that traverses your infrastructure puts more of a strain on managing multiple vLANs.
The modern origins of SDN came about through the efforts of two computer science professors: Stanford's Nick McKeown and Berkeley's Scott Shenker, along with several of their grad students. The project was called "Ethane" and it began more than 15 years ago, with the goal of trying to improve network security with a new series of flow-based protocols. One of these students was Martin Casado, who went on to found an early SDN startup that was later acquired by VMware in 2012. A big outgrowth of these efforts was the creation of a new networking protocol called OpenFlow.
Now Google and Facebook, among many others, have adopted the OpenFlow protocol in their own data center operations. The protocol has also gotten its own foundation, called the Open Networking Foundation, to move it through the engineering standards process.
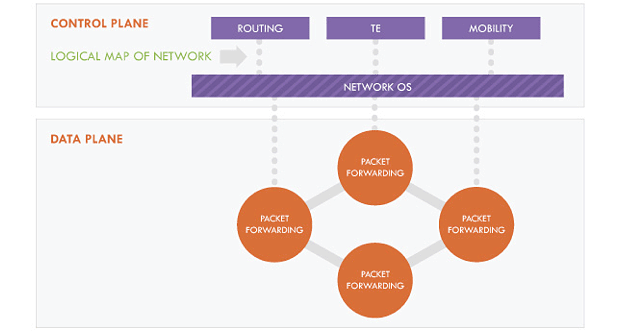
The OpenFlow topology.
OpenFlow offers a way to have programmatic control over how new networks are setup and torn down as the number of VMs waxes and wanes. Getting this collection of programming interfaces to the right level of specificity is key to SDN and OpenFlow's success. Now that VMware is involved in OpenFlow, we expect to see some advances in products and support for the protocol, plus a number of vendors who will offer alternatives as the standards process evolves.
SDN makes sense for a particular use case right now: that of hybrid cloud configurations where your servers are split between your on-premises and offsite or managed service provider. This is why Google et al. are using them to knit together their numerous global sites. With OpenFlow, they can bring up new capacity across the world and have it appear as a single unified data center.
But SDN isn't a panacea, and for the short-term it probably is easier for IT staff to add network capacity manually rather than rip out their existing networking infrastructure and replace with SDN-friendly gear. The vendors who have the lion's share of this infrastructure are still dragging behind on the SDN and OpenFlow efforts, in part because they see this as a threat to their established businesses. As SDNs become more popular and the protocols mature, expect this situation to change.
Backup as a Service
As more applications migrate to Web services, one remaining challenge is being able to handle backups effectively across the Internet. This is useful under several situations, such as for offsite disaster recovery, quick recovery from cloud-based failures, or backup outsourcing to a new breed of service providers.
There are several issues at stake here. First is that building a fully functional offsite data center is expensive, and it requires both a skilled staff and a lot of coordinated effort to regularly test and tune the failover operations. That way, a company can be ready when disaster does strike to keep their networks and data flowing. Through the combination of managed service providers such as Trustyd.com and vendors such as QuorumLabs, there are better ways to provide what is coming to be called "Backup as a Service."

QuorumLabs system architecture, showing how it can duplicate and backup Windows servers across the Internet.
Both companies sell remote backup appliances that work somewhat differently to provide backups. Trustyd's appliance is first connected to your local network and makes its initial backups at wire speeds. This is one of the limitations of any cloud-based backup service, because making the initial backup means sending a lot of data over the Internet connection. That can take days or weeks (or longer!). Once this initial copy is created, the appliance is moved to an offsite location where it continues to keep in sync with your network across the Internet. Quorum's appliance involves using virtualized copies of running servers that are maintained offsite and kept in sync with the physical servers inside a corporate data center. Should anything happen to the data center or its Internet connection, the offsite servers can be brought online in a few minutes.
This is just one aspect of the potential problem with backup as a service. Another issue is in understanding cloud-based failures and what impact they have on your running operations. As companies virtualize more data center infrastructure and develop more cloud-based apps, understanding where the failure points are and how to recover from them will be key. Knowing what VMs are dependent on others and how to restart particular services in the appropriate order will take some careful planning.
An exemplary idea is how Netflix has developed a series of tools called "Chaos Monkey" that it has since made publicly available. Netflix is a big customer of Amazon's Web Services, and to ensure that it can continue to operate, the company constantly and deliberately fails parts of its Amazon infrastructure. Chaos Monkey seeks out Amazon's Auto Scaling Groups (ASGs) and terminates the various virtual machines inside a particular group. Netflix released the source code on Github and claims it can be designed for other cloud providers with a minimum of effort. If you aren't using Amazon's ASGs, this might be a motivation to try them out. The service is a powerful automation tool and can help you run new (or terminate unneeded) instances when your load changes quickly. Even if your cloud deployment is relatively modest, at some point your demand will grow and you don't want to depend on your coding skills or having IT staff awake when this happens and have to respond to these changes. ASG makes it easier to juggle the various AWS service offerings to handle varying load patterns. Chaos Monkey is the next step in your cloud evolution and automation. The idea is to run this automated routine during a limited set of hours with engineers standing by to respond to the failures that it generates in your cloud-based services.
Application-aware firewalls
Firewalls are well-understood technology, but they're not particularly "smart." The modern enterprise needs deeper understanding of all applications that operate across the network so that it can better control and defend the enterprise. In the older days of the early-generation firewalls, it was difficult to answer questions like:
- Are Facebook users consuming too much of the corporate bandwidth?
- Is someone posting corporate data on a private e-mail account such as customer information or credit card numbers?
- What changed with my network that's impacting the perceived latency of my corporate Web apps today?
- Do I have enough corporate bandwidth to handle Web conference calls and video streaming? What is the impact on my network infrastructure?
- What is the appropriate business response time of key applications in both headquarters and branch offices?
The newer firewalls can answer these and other questions, because they are application-aware. They understand the way applications interact with the network and the Internet, and firewalls can then report back to administrators in near real time with easy-to-view graphical representations of network traffic.
This new breed of firewalls and packet inspection products are made by big-name vendors such as Intel/McAfee, BlueCoat Networks, and Palo Alto Networks. The firewalls of yesteryear were relatively simple devices: you specified a series of firewall rules that listed particular ports and protocols and whether you wanted to block or allow network traffic through them. That worked fine when applications were well-behaved and used predictable ports, such as file transfer on ports 20 and 21 and e-mail on ports 25 and 110. With the rise of Web-based applications, ports and protocols don't necessarily work as well. Everyone is running their apps across ports 80 and 443, in no small part because of port-based firewalling. It's becoming more difficult to distinguish between apps that are mission-critical and someone who is running a rogue peer-to- peer file service that needs to be shut down.
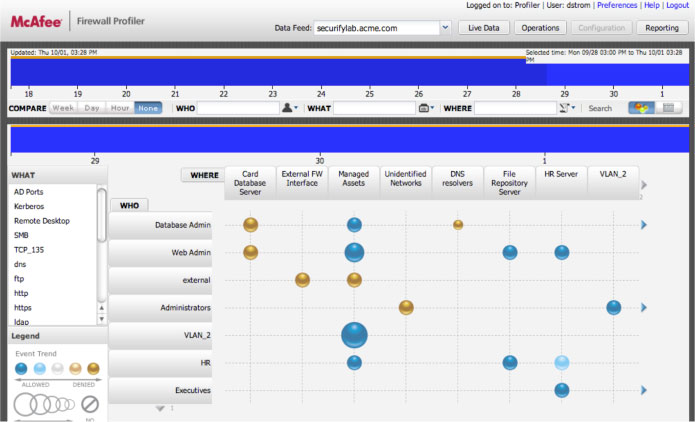
The McAfee Enterprise Firewall is an example of a new breed of applications-aware tools where the colored bubbles indicate the volume of events and firewall actions between a source (who) and a destination (where). The bigger the bubble, the more traffic.
Another aspect of advanced firewalls is being able to look at changes to the network and see the root causes, or viewing time-series effects as your traffic patterns differ when things are broken today (but were, of course, working yesterday). Finally, they allow administrators or managers to control particular aspects of an application, such as allowing all users to read their Facebook wall posts but not necessarily send out any Facebook messages during working hours.
Going on from here
These six trends are remaking the data center into one that can handle higher network speeds and more advances in virtualization, but they're only part of the story. Our series will continue with a real-world look at how massive spikes in bandwidth needs can be handled without breaking the bank at a next-generation sports stadium.
David Strom is a well-published author on networking and Internet topics. He's written two books and thousands of magazine articles spanning a 25-year career. Strom can be found at david@strom.com,@dstrom on Twitter, and Strominator.com.
No comments:
Post a Comment
Let us know your Thoughts and ideas!
Your comment will be deleted if you
Spam , Adv. Or use of bad language!
Try not to! And thank for visiting and for the comment
Keep visiting and spread and share our post !!
Sharing is a kind way of caring!! Thanks again!