With its new tablet-friendly user interface, Windows 8 is going to be a revolution for both desktop users and tablet users alike. These substantial user interface changes are paired with extensive changes beneath the operating system's surface. For both developers and users, Windows 8 will be the biggest change the Windows platform has ever undergone.
In the wake of the first demonstrations of Windows 8 in mid-2011, some unfortunate word choices left many developers concerned that Windows 8 would force them to use Web technologies—HTML and JavaScript—if they wanted to write tablet-style applications using the new Windows user interface. We thought something altogether more exciting was in the cards: we felt Windows 8 would be a platform as ambitious in its scale as the (abandoned) Windows "Longhorn" project once was. At its BUILD conference in September 2011, Microsoft unveiled Windows 8 for real and talked about application development on the new operating system. The company proclaimed it to be an entirely new, entirely different way of developing applications. Our predictions were apparently confirmed and then some.
Closer inspection reveals a more complex picture. Windows 8 is a major release, and it is very different from the Windows before it. And yet it's strangely familiar: when you peek under the covers of the new user interface and look at how it all works, it's not quite the revolution that Microsoft is claiming it to be.
Windows 8 supports all the traditional Windows applications that have been developed over past decades. But the centerpiece of Windows 8 is not its support for legacy applications. With Windows 8, Microsoft wants to develop a whole new ecosystem of applications: touch-friendly, secure, fluidly animated. The new aesthetic was known as Metro, though rumored legal issues have chased the company away from that particular name. These new applications aren't built with the time-honored Windows APIs of yore. They're built with something new: the "Windows Runtime," aka "WinRT."
WinRT isn't just a new library, though it is that in part. More so, it's a whole new infrastructure for building and assembling Windows programs. If Windows 8 is successful—and more specifically, if Metro apps flourish—WinRT will be the foundation on which Windows apps are built for decades to come.
(A quick note: since Microsoft has moved away from the "Metro" name, Metro style applications are known variously as "Windows Store apps," and "Windows 8 apps." The Developer Division tends to prefer the former, and the Windows Division the latter. Neither term is particularly satisfactory, not least because Microsoft is using the same aesthetic, with different underlying technology, on its Web properties and Xbox 360. There are signs that the aesthetic is being called "Microsoft style design," but this is terminology that few are using. As such, I'm going to continue to refer to them as "Metro style apps" or just "Metro apps.")
But WinRT is a little surprising. As new as it is, its roots are old and its lineage can be traced back to the early days of Windows. So let me take you on a journey, a trip through Windows' dim and distant past, unearthing relics of ancient history to discover the true meaning of WinRT and understand why it's more evolutionary than it appears.
A brief history of Windows: Win16
To really understand where Microsoft is going with its operating system, we first have to understand where it has been: how Windows works today and how things got to be that way.
Operating systems exist to provide services to applications. The range of services an operating system is expected to provide has grown as computing power and user demands have grown. At the most basic level, operating systems provide file handling (creation, deletion, reading and writing of files) and simple I/O (reading from the keyboard, writing to the screen, and in modern operating systems, talking to the network).
The thing that made Windows Windows was, well, windows. It was a graphical user interface with windows, buttons, icons, menus, and a mouse pointer. Windows included basic operating system features—it had APIs for file handling, for example (though behind the scenes, it deferred to DOS to do the actual work)—but to these it added APIs for graphics and windowing. Windows' graphics API was named GDI, for Graphics Device Interface, and the API for creating windows and menus, responding to mouse events, and so on, was named simply USER.
These APIs are very much of their era. Concepts that are fashionable today—object orientation, security, multiprocessor support—were irrelevant when 16-bit Windows was being developed. Software back then was developed in the C programming language if you were lucky, with chunks of assembler thrown in for good measure. APIs were designed accordingly.
With a graphical operating system came graphical applications.
Before the Internet was a household name, before the World Wide Web had even been invented, the personal computer was designed for one thing above all others: running office productivity software. PCs were for word processors and spreadsheets. That's what got them into every workplace and, increasingly, people's homes.
Windows 1.0 was released in November 1985, with the brochure shown above arriving in January 1986.
Treating a word processor as a glorified typewriter was all well and good, but the PC had so much more potential. With a multitasking, GUI operating system, Microsoft (and others) wanted to provide ways to create complex, rich, compound documents. You could take, for example, a sales spreadsheet in Excel and embed a chart from that spreadsheet into a Word document. And the company wanted to do this in a live, interactive way: update the spreadsheet, and the chart in the Word document should change accordingly. Can't do that with a typewriter.
The component revolution
In 1990, Redmond released Object Linking and Embedding (OLE) 1.0, its technology to enable just this kind of scenario. A document produced in an OLE word processor could include tables and charts from an OLE spreadsheet, and these table and chart objects could either be linked back to the originating spreadsheet file, or even use a spreadsheet file embedded within document itself. Double-clicking the charts would open the spreadsheet program and allow the data to be edited. With OLE,compound documents were a reality. In 1991, Word and Excel versions that used OLE 1.0 were released, and the OLE libraries were included with Windows 3.1, shipping in 1992.
Perhaps the single most important feature of OLE was that it was extensible. The word processor wouldn't have to know anything specific about the spreadsheet program; it wouldn't have to know what the program was called, or who wrote it. It wouldn't have to understand the spreadsheet program's file format. It just had to be able to link and embed OLE objects using the OLE libraries. It could perform standard actions on OLE objects—such as "open this object up for editing." The OLE infrastructure would even make sure the right program got started up, and that when that program saved its data, it got put back in the right place.
OLE 1.0 was a little clumsy to use, and it was quite singular in its purpose: to compound documents. But Microsoft liked the concept of having software components that could communicate with each other in a standard way, even without knowing much about each other. The company decided to flesh out this core technology to make it into a general-purpose component technology. Unaware of how annoying it would later be to have a name that's all but unusable by Web search engines, they named it COM: Component Object Model.
COM
There are a few parts to COM that are useful to understand. The central concept to COM is software components that expose one or more interfaces: named groups of (typically related) functions that the component implements. Microsoft publishes hundreds of such interfaces implemented by Windows components. Many of them are also implemented by third-party components, allowing them to slot into applications as if they were part of the operating system.
For example, Windows has a large COM-based framework, Media Foundation, for constructing media applications (music and video playback and capture, that kind of thing). This includes an interface for "media sources." These components represent, say, a stream of audio data from a CD, audio/video data from a DVD, video from a Web broadcast, and so on. Microsoft provides a number of components that implement this interface with Windows, for well-known sources such as audio CDs and DVDs, allowing Media Foundation programs to use these sources in a common way. Third parties can also implement the same interface for custom streams—perhaps in the future we will have holographic data cubes instead of DVDs—and in doing so will allow existing Media Foundation software to use the sources, without ever having to know any specific details of what they represent.
COM itself defines a number of interfaces components can implement. The most important of these is called
IUnknown. Every single COM component implements IUnknown. The interface does two things: it handles reference counting, and it's used for getting access to the interfaces that a COM component actually implements.
Reference counting is a technique for managing the lifetime for software objects. Each time a program wants to hold on to an object, it calls a function
AddRef() that's part of IUnknown. Each time it has finished with the object, it removes a reference with IUnknown's Release() function. Internally, every COM object keeps count of how many references there are, increasing the count for eachAddRef(), and decreasing it for each Release(). When the count hits zero—no more references to the object—the object tidies up and destroys itself, closing any files or network connections or whatever else it might have needed. This frees the memory it uses.
Reference counting is not a perfect system. It has a few well-known issues. If two objects reference each other, even if nothing else references them, they will never be destroyed. That's because each object will think it has a count of one, and since neither object will
Release() the other, the memory is lost, leaked, until the program ends. The problem is known as circular references. This can be easy to detect with only two objects that reference each other directly, but in real programs there can be chains of many hundreds of objects, making it difficult to track down exactly what has gone wrong. It's also not safe: a program can accidentally try to use a component even after it has Release()ed it, and COM does nothing to detect this. The result can be harmless, but it can also be a serious security flaw.
COM objects can expose a lot of different interfaces. Getting access to each of the interfaces a COM object supports is done with a function called
QueryInterface(). Every single interface used by COM has an associated GUID, a 128-bit identifier that's usually written as a long sequence of hexadecimal digits wrapped in braces. The general appearance of these strings, though not their actual values (such as {00000000-0000-0000-C000-000000000046} for IUnknown), will likely be familiar to any Windows users who have poked around their registries. They also crop up in Event Viewer and various other places in the operating system.
COM components, the EXEs and DLLs that implement COM interfaces, also have GUIDs. The mapping from GUID to EXE or DLL is stored in the registry. Indeed, that's what the registry is for, registering these GUID to DLL mappings. An application uses these component GUIDs (called "CLSIDs," class IDs) to tell the operating system which components it wants to create. To retrieve a specific interface from the component, the application passes the GUID of the interface (or "IID," interface ID) of interest in to the component's
QueryInterface() function. If the component implements the interface, QueryInterface() gives the application a way of accessing the interface. If it doesn't, it gives the application nothing.Cross-language COMpatibility
COM also defines an Application Binary Interface (ABI). An ABI is a lower-level counterpart to an Application Programming Interface (API). Where an API enumerates and describes all the functions, classes, and interfaces that a program or operating system lets developers use, the ABI specifies the specific meaning and usage of that API. For example, the Windows ABI specifies that the standard integer number type, called
int in C or C++, is a 32-bit value. The ABI also specifies how functions are called—for example, which processor registers (if any) are used to pass values to the function.
The COM ABI also defines how programs represent interfaces in memory. Each interface is represented by a table of memory addresses. Each memory address (or "pointer," as they are known) represents the address of one of the interface's functions. The pointers in the table follow the same order as the functions that are listed in the interface's description. When an application retrieves an interface from a component using
QueryInterface(), the component gives the application a pointer to the table that corresponds to that particular component.
This representation was chosen because it's the natural way of implementing classes and interfaces in C++. C++ also provides the name for this table of pointers; it's called a "v-table," with "v" for "virtual," because C++ describes these interface functions as "virtual" functions. Every C++ object that implements interfaces contains within it a set of pointers, one per interface, with each pointer pointing to the v-table representing an interface. These pointers are sometimes called v-ptrs ("virtual pointers").
It is with v-ptrs that functions like
QueryInterface() actually work: when QueryInterface() wants to give an application access to a particular interface, it gives the application a v-ptr to the interface's v-table.
While based on C++'s approach to objects, COM is designed to be language agnostic. It can be used with Visual Basic, Delphi, C, and many other languages. It's the ABI that ties these disparate languages together. Because they all know what an interface "looks like" and how it "works," they can interoperate.
Released in August 1995, Visual Basic 4.0 was the first version capable of creating 32-bit Windows programs.
The final part of the COM puzzle is the Interface Description Language (IDL). The actual interfaces are (or at least, can be) written in a language that isn't a programming language as such. Instead it's a simpler language that's used to describe COM interfaces (and their corresponding GUIDs) in a standard, consistent way. These IDL descriptions then get compiled into a type library (TLB)—a binary representation of the same information—which is then typically embedded into the component's DLL or EXE, or sometimes provided separately, and sometimes not provided at all. Programs and development tools can inspect these TLBs to determine which interfaces a particular component supports.
Microsoft saw that COM was good. Redmond started using COM just about everywhere. OLE 1.0 begat COM, and COM begat OLE 2.0: the OLE API was reworked to be just another COM API.ActiveX, a plugin interface for GUI components and scripting languages, infamously used as the plugin architecture for Internet Explorer, was a COM API. Even new APIs such as Direct3D and, as mentioned above, the new Media Foundation multimedia API are all built on COM (or at least, mimic COM). Since its invention, COM has grown to permeate Windows.
COM is a large and complex system. It has to be; it has to handle a wide range of situations. For example, COM components that create a GUI have to abide by the specific rules that the Windows GUI API has for threading: any given window can only be modified by a single thread. COM hasspecial support for components that need to live by these rules to ensure that every time an interface's function is called, it uses the right thread. This isn't suitable for most non-GUI components, so COM also has support for regular multithreaded components. You can mix and match—but you have to be careful when you do.
Still, Microsoft used COM just about everywhere. In particular, it grew to become the foundation of Microsoft's enterprise application stack, used for building complex server applications. First Microsoft developed Distributed COM (DCOM), which allows an application on one machine to create components on another machine over a network and then use them as if they were local. Then came MTS, Microsoft Transaction Server, which added support for distributed transactions (to make sure a bunch of distributed components either all succeeded in updating the system, or all did nothing, with no possibility of some succeeding but others not).
Finally, in Windows 2000, came COM+. COM+ subsumed DCOM and MTS and added performance and scalability enhancements. It also added more features designed for enterprise applications.
A proliferation of APIs
Concurrent with this development of OLE and COM, Windows itself was being developed and expanded, sprouting new APIs with every new release. 16-bit Windows started out with GDI, USER, file handling, and not a huge amount more. In late 1991, an update for Windows 3.0, the Multimedia Extensions, was released, providing a basic API for audio input and output and control of CD drives.
Multimedia Extensions were rolled into Windows 3.1, but just as Windows 3.0 had an extension for sound, so Windows 3.1 gained one for video, with Video for Windows in late 1992. Again, Windows 95 would have this as a built-in component.
Microsoft never planned to extend the 16-bit Windows API to 32 bits. The plan was to work with IBM and create OS/2 2.0, a new 32-bit operating system with an API based on the 16-bit OS/2 1.x APIs. But the companies had a falling out, leaving IBM to go its own way with OS/2 and forcing Microsoft to come up with a 32-bit API of its own. That API was Win32: a 32-bit extension to Win16.
Windows NT 3.1 arrived on the scene in July 1993.
The 32-bit Windows NT was released in 1993, and this greatly expanded the breadth of the APIs. Though it included 32-bit versions of USER and GDI to ensure applications were easy to port, the 32-bit Windows API did much more. For example, it included support for multithreading and the synchronization mechanisms that go hand in hand with multiple threads. Windows NT hadservices, long-running background processes that didn't interact with the user (equivalent to Unix daemons), and had an API to support this. Windows NT introduced concepts such as security and user permissions; again, there are APIs to support this.
Windows 95 brought API development of its own. DirectX was first introduced on that operating system. Exactly what's inDirectX has varied over the years; at one time or another, it has included a 2D API (DirectDraw), a 3D API (Direct3D), an audio API (DirectSound), a joystick, keyboard, and mouse API (DirectInput), a networking API (DirectPlay) and a multimedia framework to supersede both the Multimedia Extensions and Video for Windows (DirectShow). Many of these are now deprecated, but Direct3D and DirectShow are still important Windows components (even though DirectShow has been partially replaced by the newer Media Foundation).
The coding styles and conventions used by these different APIs vary, according to the whims of the development teams that created them and the prevailing coding fashions of the time. The result of all this is that the Win32 API is not some monolithic, consistent thing. It's a mish-mash. Really old parts, parts that are inspired by Win16—including file handling, creation of windows, and basic 2D graphics—are still C APIs. So are parts that correspond closely with core kernel functionality; things like process and thread creation are all C-based. But newer parts, parts without any direct Win16 predecessor, are often COM or COM-like. This includes DirectX, Media Foundation, extensions and plug-ins for the Explorer shell, and more. The use of COM or COM-like mechanisms even extends to certain drivers.
Overwhelming COMplexity
Big and sprawling as COM may be, it isn't bad technology. It's complex because it solves complex problems, and in practice, most applications can avoid a lot of the complexity. Software that usesMedia Foundation, for example, only needs a small and easily understood subset of COM functionality. Some things, such as Direct3D, don't even play by the rules properly, which is bad if you want to treat them as if they're proper COM, but convenient if you don't.
But there was a problem with all that complexity. The only mainstream programming language that supported all of COM's capabilities was C++ (or C, but much less conveniently). Visual Basic, though widely used in enterprise development, could only use a subset of COM's capabilities. This wasn't all bad, as it meant that it handled a lot of complexity automatically, but was nonetheless limiting. The problem with C++ is that it is itself a complex language, and C++ COM programs tend to be prone to the same kind of bugs and security flaws that have plagued C and C++ for decades. And unlike Visual Basic, C++ did virtually nothing automatically.
Microsoft has tried to make C++ developers' lives easier. COM requires quite a bit of infrastructural scaffolding to be written by the developer. This was both laborious and repetitive, as the code would be essentially the same each time. A non-standard extension to C++, "Attributed C++" (introduced in 2002), enabled the compiler to do this work instead of the developer. Another non-standard extension,
#import, would use TLB metadata to generate nice, C++-like classes simply using (though not creating their own) COM components.
Helpful though these were, using COM and C++ still meant wrestling with grizzly bears on a daily basis. So this left developers with a choice: safe, easy, but limited Visual Basic, or unsafe, complex, fiddly, powerful C++.
Meanwhile, Sun was busy inventing and developing Java.
Caffeinated competition
Sun wanted Java to be used everywhere. Desktop applications, server applications, little embedded control systems—everywhere. That didn't happen, as it never really made any inroads on the desktop. But Java carved out a substantial role for server applications.
The Java name encompasses many things. There's the Java language, which looks and feels familiar enough to C++ developers that they can quickly make themselves feel comfortable. There's the Java library, a rich and fully featured set of libraries giving developers instant access to the building blocks they need to create complex applications. And finally there's the Java virtual machine. Rather than producing native, platform-specific programs, Java programs were compiled to an intermediate form,Java bytecode, that was verified and then executed by the Java virtual machine.
 Java never had much success on the desktop
Java never had much success on the desktop
This virtual machine, and the verification it performed, meant that Java was immune to the kinds of problems that have plagued C and C++ since their inception. Buffer overflows and heap corruption were rendered harmless or impossible.
Java also solves COM's reference counting problem, instead using a system called "garbage collection." With garbage collection, the virtual machine examines the running program, looking for objects that are currently being referenced by the program's threads (both directly, by the threads themselves, and indirectly, by objects that are in turn referenced by the threads). These objects are kept aside because they're still in use; everything else is then cleaned up. This eliminates the circular reference issue, as only objects that threads can actually see and use are retained. It also eliminates the possibility of using an object after it's being
Release()ed: programmers don't have to callRelease() at all, so can never call it in the wrong place.
As Java matured, it gained a lot of the features found in COM+, including DCOM's ability for a program on one computer to reference objects on another computer over a network, as well as MTS's transaction capabilities.
Java included these advanced features but also managed to avoid a lot of COM's complexity. Java is naturally, natively multithreaded, so it didn't need to include special support for single-threaded components. Java doesn't need separate IDL or TLB files; the interface definitions from the language itself are used instead of IDL, and the compiled Java bytecode includes enough extra information to fill the role played by TLBs.
With Java, Sun was offering enterprise developers something that Microsoft couldn't: the powerful capabilities of COM, plus a language as safe and easy to use as Visual Basic without the problems of C++.
Enter .NET
Microsoft didn't want to lose enterprise developers to Java, so the company needed to react. The response was first codenamed COM 3.0, then the Common Object Runtime. But the final name chosen paid homage to COM's hostility to search engines: though released very much in the Internet era, Microsoft named it the equally unsearchable .NET. Version 1 was released in 2002.
Where Java had the C++-derived Java language, Microsoft had its new C++-derived C# language. Where Java had the extensive and capable Java library, Microsoft had its new .NET Framework library. Where Java had the Java virtual machine and bytecode, Microsoft had IL (Intermediate Language) and a garbage collected, virtual machine-like runtime environment.
As a spiritual successor to COM, .NET replicated important features that COM had. For example, it was designed to be used from multiple programming languages. .NET includes a specification describing a common core set of language features. As long as programs stick to this core feature set, they can freely mix C#, C++, Visual Basic.NET, and other .NET languages. While COM needed mechanisms such as IDL, TLBs, and
QueryInterface() to achieve this, with .NET it was all built in. Just as with Java, compiled .NET programs include the information that TLBs would provide in COM. In the .NET world, it's called ".NET metadata," and again like Java, it gets generated automatically.
.NET did not replace everything COM did. Instead of reinventing the wheel, complex enterprise features such as distributed transaction processing were built on top of the services provided by COM+. Microsoft also made it very easy for developers to use existing COM code from within .NET, and vice versa. For example, COM TLBs can be converted into .NET metadata, allowing .NET programs to treat COM components as if they were written in .NET.
Just as Java had found success with enterprise developers, so too did .NET. It was developed by Microsoft's Server and Tools division, which is responsible for products such as Visual Studio, SQL Server, and IIS. Customers warmly welcomed the more productive, more powerful development framework. Just as with Java, however, .NET found less success when it came to conventional desktop applications. It didn't go unused for desktop applications, not by any stretch. But the applications tended to be internal, corporate line-of-business programs, rather than published, shrink-wrapped commercial software.
Though .NET was designed to be multi-language, not every language was created entirely equal. For example, some programming languages, including C#, C++, and Java, are case-sensitive—that is, they treat a function named "Add" as different from one named "add." Others, such as Visual Basic, are case insensitive, treating them as equivalent. Accordingly, case-sensitive languages can make functions and classes whose names differ only by case; case-insensitive ones cannot. The C# language, developed in conjunction with .NET, can do most things that .NET permits, but not quite everything. To fully exploit the full power of .NET requires direct use of IL (equivalent to the age-old practice of assembly language programming); the next best thing is to use C++.
Standard C++ doesn't really support all the features .NET enables, so Microsoft had to add some extensions to the language to fill in the gaps. Its first attempt, Managed C++, was rather ugly and clumsy, requiring developers to scatter lots of words like
__gc and __interface over their code.
The situation improved in 2005, with C++/CLI, a new, cleaner syntax. C++/CLI feels like a new language, one that supports both traditional C++ concepts such as pointers and manual memory management but also .NET concepts such as garbage collection and interfaces. The full details of C++/CLI are relatively unimportant, but a couple of features merit mention. Traditional C++ uses
* to mean "pointer," so int* means "pointer to integer." For pointing to .NET objects, which use garbage collection, C++/CLI uses ^ instead of *. So for example, Int32^ means "pointer to garbage collected 32-bit integer." To define a class, traditional C++ uses class; to define a .NET class, C++/CLI usesref class.
.NET's reception among Microsoft's sizable community of developers was, for the most part, positive, but not uniformly so. Developers writing custom business-specific, line-of-business applications, whether browser-based or desktop applications, leapt on it. They quickly adopted .NET and the various technologies built on top of it. This is unsurprising in many ways; these are the same developers who had been using the COM-based Visual Basic 6 and, for Web applications, Microsoft's COM-based Active Server Pages. .NET, as a kind of "son-of-COM," was a logical next step for these developers.
An averted revolution
The situation for developers of shrink-wrap applications was rather different, however. Most of these developers had an existing legacy of traditional C or C++ code written to use Win32. Porting these applications to use .NET would have been a major undertaking, and as a result, most didn't.
The story within Microsoft was rather more complex. There was an initial flurry of excitement. .NET was viewed not just as a kind of Visual Basic 6 replacement, but as the future of Windows development, an essential part of future Windows versions. Microsoft wanted to put .NET everywhere. For example, the operating system eventually named "Windows Server 2003" was, for much of its development, named "Windows .NET Server 2003."

The unofficial Windows Longhorn logo
This was to be just the start; the real .NET revolution would occur with Windows Longhorn. Windows Longhorn promised to be radical. In Windows XP and Windows (.NET) Server 2003, .NET was in a sense "just another application." .NET couldn't do anything that Win32 couldn't do, and behind the scenes it was all just Win32. It was great deal easier and safer than using Win32 directly, sure, but still just Win32. In Longhorn, that was going to change.
The most important element of Longhorn was a new API called "WinFX." This had the "Fundamentals," consisting of .NET, and some smaller bits and pieces like a system for installing and deploying software. There were three "pillars"—a new 3D-accelerated API paired with an XML-based language (XAML) for writing GUI applications, named "Avalon"; a framework for communications, called "Indigo"; and a final component, WinFS, which was to be a sort of fusion of a relational database and a filesystem. WinFS was postponed early in Longhorn's development, though not until Microsoft had talked up the technology and shipped a preview version.
In the Longhorn world, Win32 as we know it, the mishmash of C and COM APIs, many of which have a design dating back to the late 1980s, would be frozen. No new features would be added; their sole purpose would be backwards compatibility. Instead, new features would be part of Avalon, Indigo, WinFS, or the Fundamentals. These new features would have no Win32 counterpart. The difference was most acute with Avalon; it was to be resolution-independent, vector-based, and Direct3D accelerated. The old Win32 graphical and windowing features had no comparable features and they never would. Avalon would not sit on top of the Win32 APIs. It would sit alongside them, as an independent, separate, faster, easier-to-use, more powerful alternative.
Longhorn made disruptive changes to Windows development, and this made developing Windows itself enormously challenging for Microsoft. For example, the Explorer shell was redeveloped to depend on the WinFX. But because WinFX weren't themselves finished, they kept changing, meaning the Explorer developers had to keep changing their code to keep pace. With the right management, structure, and organization, this kind of upheaval and churn can be kept in control, but it overwhelmed Microsoft. Windows was too complex, too interconnected, too big.
Compounding this was the WinFS database-like filesystem. This posed genuine technical challenges—nobody really knows how best to combine the behavior and performance characteristics necessary for a general-purpose filesystem with the structure and complexity of a relational database, and make the two approaches work in concert. Microsoft discovered it had bitten off more than it could chew. While WinFS was postponed prior to the abandonment of the broader Longhorn project, this had knock-on effects of its own: applications that had been rewritten to work with WinFS now needed to be rewritten again to work with a plain old filesystem.
So Microsoft essentially cancelled Longhorn and produced Windows Vista instead. Some elements of Longhorn were salvaged. Longhorn's new framework for writing video drivers that made them much more resilient against crash-inducing bugs and Direct3D acceleration of the desktop was preserved. Avalon and Indigo were also both retained: Avalon became "Windows Presentation Foundation" (WPF), Indigo became "Windows Communication Foundation" (WCF), and both shipped as part of .NET 3.0.
But the broader goals of Longhorn were abandoned. Windows itself remained an operating system written in, and designed for, native code. Windows Vista added new C and COM APIs, and these APIs had no managed code .NET counterparts. The only part of desktop Windows Vista to depend on .NET was Media Center, but even this didn't use the new Longhorn-originated WPF or WCF features.
Even with these greatly scaled back goals, Windows Vista struggled on the market, particularly as device manufacturers and software developers did a poor job of readying themselves for the new video driver system and tighter security.
Windows 7 built on Windows Vista, polishing a number of rough edges, and by the time it was released the hardware and software developers had mostly caught up with the changes that Windows Vista introduced. Windows 7's launch was much smoother than Windows Vista's, and the operating system has been nothing short of a phenomenal success.
Yet still the API remained a mishmash of C and COM, and still Media Center was the only part of desktop Windows to use .NET code. The managed dream was dead.
The necessity of change
Windows 7 has been highly successful. But Microsoft still has a problem. The changes that the company wanted to make for Longhorn were not whimsical or unnecessary. They were motivated by a desire to fix genuine problems with the Windows platform.
The ancient USER API makes the development of good-looking, attractive Windows applications extraordinarily difficult. There are many reasons, such as clunky APIs and missing features, but at its core, perhaps the biggest problem is that USER is essentially inextensible. If a developer wants to create, say, a menu that acts exactly like the standard operating system menu but with some small extra feature (for example, he might want to support the drag and drop, similar to the Favorites menu in Internet Explorer) he generally has no option but to reinvent the entire menu system from scratch. He cannot take the built-in menus and extend them with a little extra feature; he has to develop an entirely new workalike that replicates all the standard menu functionality and then adds the extra things he wants.
This is one of the big reasons that almost every major Windows application looks and feels different; it's why even the applets that ship with the operating system have a wide variety of styles and appearances. Developers create all kinds of layers on top of USER to add the extra bells and whistles that they want, but all of these layers work slightly differently. The differences are often quite minor—drawing menu bars slightly wrong, treating keyboard input slightly differently, omitting rarely-used scroll bar features—but are nonetheless noticeable. Microsoft is no exception here; the company has a number of different toolkits designed to make Win32 easier, and they too diverge from the platform look and feel.
The GDI graphics API is also a problem. It's built around manipulation of 2D bitmap graphics, which were all the rage 20 years ago. But nowadays we have video cards that dedicate hundreds of millions of transistors to the task of crunching on 3D vector graphics. GDI can exploit none of these capabilities. GDI's bitmap-oriented design also makes it much harder to produce resolution-independent applications—applications that will work well on the 300 dpi screens found on smartphones, for example.
Programming styles have also changed substantially since the late 1980s when many of these APIs were designed. The biggest shift perhaps is the need for multithreading and asynchronous processing to make good use of modern multicore processors. While Win32 has the low-level support needed to write such applications, it doesn't make it easy.
Demands for both greater security and productivity have also made runtime-based environments—like Java, .NET, or scripting languages like Python, JavaScript or Ruby—much more important.
The Longhorn plans went a long way towards addressing these demands. Avalon/WPF is a vast improvement on GDI and USER. While it's still possible to create ugly applications that don't conform to the behavioral standards that should be respected, WPF makes it a lot easier to make attractiveapplications that do conform. In typical WPF applications, the GUI itself is laid out and designed using XAML, with the programmatic plumbing done in C# or Visual Basic .NET. Microsoft has design tools that produce XAML, allowing designers to create interfaces and produce XAML independent of coders coding the application. WPF interfaces are made of discrete components, and these components can be cleanly extended and augmented to provide new behavior when necessary—without having to recreate each component entirely from scratch just to add one or two extra features.
Longhorn also made nice, safe, productive .NET a first-class citizen, giving developers the improved security and productivity they desire.
Longhorn might not have done everything that a modern operating system needs to do—it predated the large increase in processor core/thread count that has occurred over the last few years, so it did not do as much to improve the development of multithreaded, multiprocessor applications as we might like. But it represented a large step forward, and arguably a necessary step forward.
Split developer communities
The Longhorn vision was not without its problems, however. The chief problem was it depends on .NET. While .NET has seen substantial uptake among a certain kind of developer, it has left others out in the cold. The early adopters of .NET were developers working on internal line-of-business (LOB) applications, and even as the platform has grown and evolved, that hasn't really changed. Developers of large desktop applications—think Office, or Photoshop, or even games—have stuck with native code and the Win32 API.
Migrating these applications to an all-new .NET-based system would be an enormous undertaking, for little direct gain. .NET certainly makes new development easier, but giving up an existing, widely-used, thoroughly-debugged codebase just for the promise of easier development just isn't going to fly. As easy as .NET may be (relative to native Win32), it's never going to be as easy as not porting the application you already have. "No work" is always going to beat "some work."

Like its predecessors, Office 2010 is a Win32 application
In many ways, Microsoft's divisions are catering to two different developer communities, with little overlap or commonality between them. Windows division is building a platform for the native code developers: large applications, often with a considerable legacy, high-performance games, or complex server systems such as databases. Server and Tools is building a platform for the in-house developer, the small teams churning out CRUD database-driven LOB applications, corporate intranet sites, and the like. With XNA and Silverlight (which started life as a cut-down version of WPF for embedding into browsers, but has grown into something more) on Xbox 360 and Windows Phone, Server and Tools' market has grown now to include more hobbyists and aspiring developers on new platforms. Yet, they're still not really addressing the demands of the native code developers.
Conversely, the Windows team has done little to improve the lives of these busy, if unglamorous, developers. The very fact they turn to technology like .NET and WPF is because Win32 itself is so ill-suited to this kind of development. Except in one area, the worlds of the two developer communities don't really overlap. In Windows Vista and Windows 7, Windows team has added all sorts of new technologies to Windows: a new audio subsystem that's suitable for low-latency, realtime audio applications, a transactional filesystem, a new system for color management (to ensure what you see on-screen matches what you print), Direct3D 10 and 11, to name a few, all either C or COM APIs. But these are of little or no relevance to the .NET developer community. They're aimed instead, overwhelmingly, at developers who already have existing Win32 programs and who aren't going rewrite them from scratch to use .NET.
That big area of overlap is the creation of user interfaces; it's something that all developers have to do, whether they're making internal applications to help their company run better, or million-selling shrinkwrap software. In this one area, the Windows team had little to offer developers. The core operating system has gained some new standard GUI components—Windows 7 includes a ribbon control that applications can use, for example—but they still build on the clumsy and inextensible USER paradigm. Win32 desktop developers could only look at WPF with a sense of envy and some regret; there's nothing like it for them.
The indomitable iPad
Had the computer industry remained the same as it was in the mid-2000s, this situation might never have changed. Windows, built by the Windows division, would remain a native code platform with an awful GUI API built on top of C and COM. .NET, built by the Server and Tools division, would remain a runtime environment whose biggest customers were writing in-house business applications. .NET would never be an equal peer to native code, so .NET developers would never have the same easy access to new operating system features that their native code counterparts had. And native developers would never have access to anything like WPF, or .NET's convenient multithreading features.
This schism might have remained forever, were it not for the tablet revolution.

Microsoft's Courier tablet never saw the light of day.
Microsoft is no stranger to the tablet market. The company's numerous tablet efforts have fared poorly in the market, however, chiefly because the operating system itself, and the applications running on it, don't have a user interface that's suitable for tablet computers.
It took a long time for Microsoft to realize that effective touch applications had to be built with touch in mind from the outset, but realize it has, and Windows 8's new Metro UI and Metro-style applications will give Windows the tablet interface it has always needed, but always lacked in the past.
Once the decision had been made to give Windows 8 a new UI, with new applications, the Windows division had the impetus—or perhaps the need—to tackle the long-standing Windows problems. Microsoft is a latecomer when it comes to new, modern, finger-friendly tablets, and to hit the ground running, the company needs Metro-style tablet applications, and it needs them to be high quality, with consistent user interfaces that show off the platform as its best.
This meant creating an API and environment that makes developing these applications easy, and that makes exploiting modern hardware easy.
That API is WinRT, the Windows Runtime.
WinRT introduced
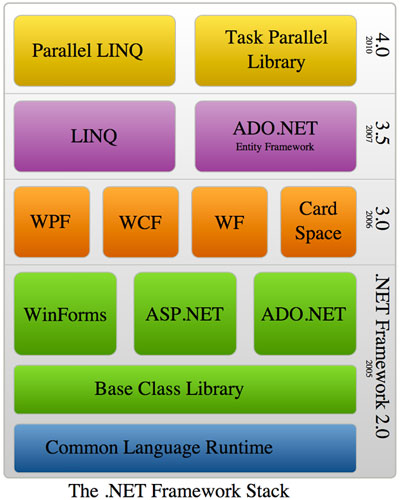
The customary way of introducing WinRT is to produce a block diagram of the operating system that shows how major components of Windows 8, including Win32, WinRT, languages like C# and C++, the kernel, and more, all fit together. Microsoft's own diagram looks like:

Microsoft's diagram presents WinRT as an independent subsystem built directly on top of the Windows kernel, leaving Win32 behind.
That diagram isn't terribly accurate, and it has become sport to try to fix it to make it more accurate.
Diagrams are useful things, and showing all the different interdependencies in the Windows 8 software stack is indeed a useful thing to do, so I'll have a stab at producing my own later on, but Microsoft's diagram is enough to get started with for a high-level overview of WinRT.
The problem isn't just the diagram. Accurate, consistent terminology is also notable by its absence, with "WinRT" itself taking on different meanings in different contexts. In Microsoft's diagram, WinRT is the only API used by Metro-style apps, and is exclusive to Metro-style apps. That's not exactly right.
For the purposes of this article, I'm going to take a fairly narrow view of "WinRT." I can see an argument for a more expansive take on "WinRT" but I think the narrower view is more useful, as it provides an easier way of distinguishing between new and old. So some of the lines I'll figuratively draw may differ from some of Microsoft's official documentation. I can live with that; it'll agree withother pieces of official documentation.
The WinRT name stands for "Windows Runtime." However, this isn't a runtime in the same way that Microsoft's .NET Runtime was a runtime, or the way Oracle's Java Runtime Environment is a runtime. In the .NET and Java cases, the runtime is a relatively large software component that provides a virtual machine environment, garbage-collected memory, various kinds of code safety verification, and more. The .NET and Java runtimes are intimately involved in virtually everything a .NET or Java program does, providing extensive infrastructure to software developers.
WinRT offers nothing quite like those runtimes. WinRT is a set of software libraries that provides an API offering a range of services—graphics, networking, storage, printing. In addition to this, there is a relatively small infrastructural component.
All Metro-style applications on Windows 8 will use WinRT. WinRT supports three kinds of application: C++, C# or Visual Basic with .NET, and, in a new addition for Windows, JavaScript. For the most part, the WinRT API is equally accessible from each of these languages. Metro applications are all GUI applications, and for creating those GUIs, WinRT has two options: C++ and the .NET languages use XAML; JavaScript uses HTML and CSS. WinRT's infrastructure enables these C++, C#, and JavaScript applications to load and use the various libraries that provide the WinRT APIs, and handles some of the translation between the different languages.
COM: back in fashion
Microsoft had two competing technologies that were suitable as the basis of a modern API—COM and .NET—but each had drawbacks. .NET has rich metadata, safe programming languages, and fits neatly with many conventions of modern programming languages (such as their use of interfaces and object-oriented inheritance). On the other hand, .NET uses a complex runtime with a virtual machine, rather than native code, which potentially exacts a performance penalty, and is somewhat awkward to use and integrate with existing native C and C++ programs.
COM is weaker in many regards—less descriptive metadata, no built-in notion of inheritance, unsafe programming languages, and in most ways far more awkward to use than .NET. But COM does have an important advantage: it has no virtual machine, being native code from the ground up. COM is also the technology used by many of the big, old Windows programs, including the all-important Office.
Within Microsoft, there are also certain political considerations at play. Internal opinion about .NET is divided. Many teams use the technology to good effect and regard it as important. The Windows division ("WinDiv"), however, has a different view. The many developmental difficulties that occurred during the (essentially abandoned) development of Windows Longhorn were attributed, at least in part, to the use of .NET code. The team also believes that native C++ development is what most developers want. This has tended to lead to an avoidance of the use of .NET even when it's an appropriate or desirable technology.
When the Windows team created WinRT, indications are that these non-technical concerns weighed at least as heavily as any technical reasons. As a result of this distaste for .NET, combined with COM's native nature and extensive use in major pre-existing Windows applications, the decision was made: WinRT is built on COM.
But it's COM with a twist.
Not your grandmother's COM
WinRT is built on COM, and those mainstays of COM programming—
IUnknown, reference counting, interfaces, and GUIDs—are still fundamental to WinRT, but this is not the COM of the early 1990s. It's a cleaned up, tidier, more powerful version of COM.
WinRT adds a second interface to the essential
IUnknown, called IInspectable. Every WinRT component implements both IInspectable and IUnknown.IInspectable has three methods. First is GetIids(), which allows a WinRT program to ask a WinRT object which interfaces it supports. Perhaps surprisingly, IUnknown doesn't have such a method; QueryInterface() allows the user of a component to ask a COM object "Do you support a particular interface, and if so, tell me where its v-table is," but if the user wanted to know all the interfaces supported by a COM object, it has to trawl through TLBs.
The second method is
GetRuntimeClassName(), which returns the component's exact name. Given such a name, programs can ask Windows to load the relevant metadata for the component. Thus, this function provides a bridge between an object in memory, and the detailed information about all the object's interfaces and methods stored in the metadata files.
The third method is called
GetTrustLevel(), which as best I can tell has no explicitly documented purpose. In principle there is a trust system, where code can be divided. Code that requires "full trust" could do anything to the system (as long as it has the relevant Windows permission). Then there's code that requires only "partial trust" (which is supposed to be safe).
In the .NET world, the amount of trust given to a program depends on things such as where it comes from (programs run from the network are traditionally given only partial trust) or whether they come from a developer you trust. Programs running under "partial trust" can only perform a subset of operations; they cannot read and write to arbitrary locations on the disk, for example. How this trust system maps to WinRT and the sandboxing used to segregate new Metro-style applications from each other and the rest of the operating system is unclear.
The other big change, and perhaps the most important single change that Microsoft has made, is the way metadata is handled in the new COM. Instead of using TLBs to carry around metadata, the new COM uses .NET's metadata format. For .NET programs, the metadata is built-in. For native C++ programs, it's stored in standalone files with the extension .winmd, for Windows Metadata. JavaScript programs can consume Windows Metadata, and hence access components built in C# or C++, but cannot create their own. This in turn imposes a number of other limitations on JavaScript programs.
This WinMD metadata is central to WinRT's multi-language support. It's the common element that every language, whether native C++, C# (or some other .NET language), or JavaScript understands. The WinRT infrastructure uses the metadata to generate what Microsoft is calling "projections" into each language.
Projecting
C++, .NET, and JavaScript all have very different ideas of what it is to be "an object." JavaScript, for example, is very dynamic: objects can be extended to gain new functions at runtime, for example. C++ is very static; everything that an object can do gets baked in when the code is compiled. C# can perform some of the tricks that JavaScript does (though not as conveniently or simply as JavaScript does them), but for the most part it's close to C++. The projection system in WinRT is used to bridge these different takes on "objects" so that components can be made available to any language.
The C++ case is the simplest. WinRT uses COM at its core, and COM natively uses C++'s v-tables, so for C++, there's not much in the way of "projecting." The C++ compiler reads the WinMD metadata of the components that a C++ program uses. So it knows where their v-tables are and what functions they contain, but that's more or less the extent of the work it has to do. At runtime, C++ programs don't need to use the metadata at all: everything they need to know about the v-ptrs and v-tables is already built in to the programs.
For .NET programs, the process is a little more complicated. .NET objects aren't laid out the same way as WinRT objects, so the system has to generate wrappers that make WinRT objects look like .NET objects for .NET programs, and .NET objects look like WinRT objects for C++ programs.
As it happens, .NET has been doing this wrapping since it was first introduced in 2002: it's used for COM interoperability. Since WinRT is essentially just COM, the wrapping infrastructure has been re-used. The wrappers have changed a little bit for WinRT—for example, the wrappers exposing .NET objects to WinRT implement
IInspectable (old COM wrappers only need to handle IUnknown), and the wrappers exposing WinRT objects to .NET use .NET metadata and GetRuntimeClassName()instead of COM TLBs—but their purpose is the same. The generation of these wrappers happens partially at compile-time, and partially at runtime.
For JavaScript, things are more complex still. Internet Explorer's JavaScript engine has actually been COM-integrated for many years, allowing scripts to create and manipulate COM objects, a capability which indirectly led to the invention of AJAX and ushered in a new era of Web page interactivity. However, this integration required the COM objects to be specially designed to enable scripting usage. They had to support a special interface, called
IDispatch, which allowed the calling script to ask the object about what functions it supported and what parameters those functions needed.IDispatch worked, and is still widely used by Windows, but as with much of COM, it was a product of its time. It's a very indirect way of combining scripting languages with COM objects that requires additional layers of translation every time a function call is made, and it requires the developers of the COM objects to provide quite a lot of supporting infrastructure. While some environments (.NET, or even ancient Visual Basic 6) provided that infrastructure for free, C++ developers had to do more of the work themselves.
So for WinRT, Microsoft appears to be doing something a little cleverer that doesn't need
IDispatch. Instead, it takes advantage of an important feature of Chakra, the JavaScript engine that Microsoft first developed for Internet Explorer 9. Unlike old JavaScript engines that interpreted JavaScript code, Chakra performs just-in-time (JIT) compilation. Imagine a fragment of a script that adds two numbers together. With an interpreter, the script engine might, for example, create two "number" objects to represent the two numbers, and then call an "add" function using the two objects as parameters. Even conservatively, this will require dozens of instructions. With the JIT compilation, Chakra would just emit x86 (or x64, or ARM) code to directly add the two numbers, something requiring just an instruction or three.IDispatch's design was a good fit for these interpreted languages, because every function got called in the same way. There was no need to generate executable code at runtime. Because Chakra already emits executable code at runtime, the indirections needed for IDispatch can be done away with. For WinRT interoperability, Chakra uses the WinRT metadata to learn about the functions that an object supports and uses this to generate the right native code needed to call those functions directly.
The new WinRT COM also makes it easier to share data between different languages. Traditional COM was quite limited. COM functions could use basic things like numbers and text strings, but passing, for example, arrays of numbers or strings was awkward, requiring the data to be packed into special objects. This is to handle the different languages that COM works with. In languages like C and C++, arrays are monumentally stupid things that don't even know how big they are. This is bad enough in C and C++, where the stupidity of arrays is responsible for numerous security flaws over the years, but it's even worse in languages like Visual Basic (which has sensible arrays that do know how big they are). If COM used C-style arrays then Visual Basic would have big problems. So traditional COM had its own kind of array, called
SAFEARRAY for interoperating between languages.SAFEARRAYs know how big they are, and so this addresses the immediate problem, but they have the side-effect of being a colossal pain to use from C++.
WinRT has an equivalent to these dumb C arrays, that corresponds to .NET's built-in arrays for .NET code, and an easy-to-use array class in C++ code. But it also goes further, using its projection system to do something that's altogether less annoying. Instead of being aimed at the lowest common denominator, as COM was, WinRT acknowledges that C++ and .NET both have extensive class libraries. These libraries include things like resizable arrays that know how long they are, and developers make extensive use of them. Instead of making developers ignore these tools of the trade and mess around with primitive C arrays, WinRT makes it easy for them to use these standard libraries.
On the .NET side, these classes already have interfaces named things like
IList. On the C++ side, the classes don't traditionally have interfaces, so Microsoft has created a set of classes that mimic the C++ standard library (and can be easily converted to and from the C++ standard library) that sport interfaces with names like IVector. The projection system then maps between corresponding .NET and C++ interfaces. .NET programmers get to use IList where it feels natural, C++ programs useIVectorA COM for the 21st century
Mechanically, the new COM works very similarly to the old COM. While for C++ and .NET developers none of these differences are particularly substantial, this new version of COM has big implications for JavaScript developers. While JavaScript is still a second-class citizen, since the COM support is only "one way," it's now a much better second-class citizen. In the olden days of COM, you had to hope that the COM object you wanted supported
IDispatch. Many didn't, due to the extra work required to do so. In new WinRT COM, JavaScript can access any WinRT object.
The new COM also tidies up important parts. Instead of trying to accommodate every language under the sun, it offers higher level support for common data structures, and uses the projection system to gloss over some of the differences between languages.
Overall, it's a better COM than COM. But it's still just COM. Streamlined COM, maybe, but still COM, and that's a problem for C++ developers, because COM programming in C++ still requires you to faff around with IDL, handle all the reference counting, use
QueryInterface() and GUIDs, and generally do a lot of work that .NET developers can safely ignore.
So Microsoft looked around in its box of tricks and came up with a solution. Just as WinRT takes the age old COM technology then updates and repurposes it for modern application development, it also does the same for C++/CLI (its .NET-oriented variation of C++). C++/CLI has been reborn as C++/CX. C++/CX makes use of the same extensions that C++/CLI adds—for example, using
^ instead of *, andref class instead of class—but changes their meaning. .NET is a garbage collected environment, so in C++/CLI, ^ is used to refer to garbage collected objects. COM, however, is reference counted, so in C++/CX, ^ is used to refer to reference counted objects.
C++/CX is a superset of regular C++, so it's a good way of mixing existing legacy or third-party C++ code with new WinRT code. While you don't have to actually use C++/CX if you don't want to—regular C++ and IDL are an option, and Microsoft has added a C++ library, the Windows Runtime C++ Template Library (WRL) to make this a bit easier—if you do use it, then dealing with the COM side of WinRT is almost completely taken care of for you, giving a development experience that's as straightforward as the one that .NET developers have enjoyed for many years.
A new face for Win32
The runtime infrastructure used to provide WinRT is only half the story. The other half of the story is the WinRT software library; the collection of APIs used to actually build WinRT applications. Just as the runtime infrastructure is a new spin on an old technology, so too is the software library. But while Microsoft is happy to talk about how WinRT is built on the time-honored COM technology, you get the feeling that it doesn't want us to think of the library in quite the same way, hence the inaccurate diagram it bandies about to explain its APIs.
Microsoft's diagram places the WinRT APIs and application model directly above "Windows Kernel Services," as if WinRT's API was some alternative that was independent of Win32. C and C++ desktop applications leverage kernel services via Win32; Metro style apps access kernel facilities via WinRT.
It's a nice idea. It just isn't true.
Let's be very clear about this. There are two important ways in which it isn't true, and a third minor way. First, the WinRT library is a layer on top of Win32. It uses some new bits of Win32, such as Direct2D and DirectWrite. It uses some much older bits of Win32, such as the shell library (a disparate set of utility functions for, among other things, manipulating files and paths) and Winsock (the network API). But either way, it uses Win32. It is not a sibling of Win32, it is not an alternative of Win32; it is a client of Win32, a consumer of Win32, just like every other application.
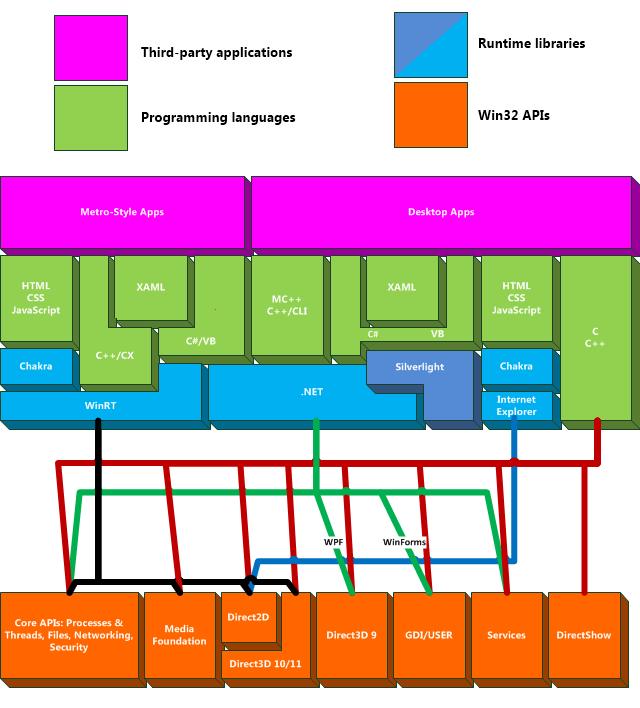
In reality, WinRT is built on top of Win32, just like .NET before it. You don't get access to all of Win32, but behind the scenes, that's all there is.
Second, Metro-style applications do not use WinRT exclusively. WinRT is very important, and I think that any reasonable Metro-style application will end up using WinRT, at least a little bit, but not exclusively. But there are also some important APIs that Metro-style applications can use, but which don't form a part of the WinRT COM world at all. Probably the most important of these is Direct3D 11. Games in the Metro world can use Direct3D 11, but they'll have to be written in C++ to do so, and they'll have to use Direct3D's traditional COM-like design without projections or metadata or any of the other pieces of WinRT infrastructure.
There are also lots of portions of Win32 available to Metro apps that have partial WinRT alternatives, but which are also exposed directly for when the WinRT alternatives aren't flexible enough. For example, WinRT has APIs for opening, reading, and writing files, but also provides access to low-level Win32 functions (some new, some old) that perform the same functions.
This is where there are some terminology differences. One could pretend that the diagram is accurate and hence decree that any API that Metro applications can use (whether using WinRT COM, traditional COM, or no COM at all) is a "WinRT API," but I think that this is not especially helpful, and such usage is not supported by most of the documentation. Rather, there is the Windows Runtime API, using the new kind of COM, and there's a load of Win32 APIs that are also permitted.
Whether this is important is a matter of opinion, but there are reasons to be disappointed that WinRT isn't true to the diagram. For a start, there are a few long-standing annoyances of Win32, such as the inability to elegantly handle paths and filenames longer than 260 characters, that are inherited into WinRT. Once baked in to an API, these things are really hard to remove, which is why Win32 is lumbered with this limit even though the Windows NT kernel is fine with paths up to 215 characters long (or thereabouts).
More subtly, this design means that Microsoft can't readily discard the backwards compatibility features that are built in to Windows and Win32. Over the years, Windows applications have come to expect Win32 to operate just so, depending not just on the official, documented behavior, but on aspects of the particular implementation. For example, some functions still work when passed values that the documentation says are prohibited. Sloppy developers accidentally use these prohibited values, see that everything works OK, and then ship their application. That's all fine, until Microsoft then wants to make the function stricter, or more efficient, or add new permitted values; the company then discovers that making this change breaks extant, shipping applications.
As a result, there's all manner of workarounds and fixes scattered throughout Windows. With WinRT being built on Win32, Microsoft is fostering a whole new generation of applications that, implicitly or explicitly, depend on these undocumented Win32 behaviors, with the result that changing them will continue to be a liability. If WinRT were built directly on top of the Windows NT kernel, as Microsoft's diagram implies, then it would no longer have to preserve these Win32 behaviors behind the scenes. As a result, future versions of WinRT will not only have to accumulate their own compatibility cruft and baggage (so that Windows 9 does not break compatibility with Windows 8, for example); they'll also have to retain and preserve all the Win32 detritus as well, ensuring long-term complexity and maintenance burden.
This is true even of the ARM-based Windows RT. Though third-party desktop applications are banned on Windows RT, this hasn't allowed Microsoft to strip out unnecessary Win32 cruft. It's all still there, powering WinRT.
The third way in which the diagram isn't true is that desktop applications (written in C++, .NET, or whatever else a developer prefers) have access to some parts of the WinRT API. While most parts of WinRT are off-limits to desktop developers (including unfortunately, the toolkit for building GUIs), a few bits and pieces are available to developers of both desktop and Metro applications. There's no real policy or consistency here; it was apparently a decision each development team could make for itself.
What's in the box?
WinRT is, at the moment, a fairly narrow API. It's built for producing Metro-style tablet apps; touch-capable GUI apps that are typically Web-connected, that make use of sensors like cameras, GPS, and accelerometers, tending to be used for content consumption rather than content creation. Accordingly, WinRT can't be used to create Windows services, or desktop applications, or extensions for things like Explorer. Particular emphasis is placed on being highly responsive to the user ("fast and fluid" is Microsoft's catchphrase). WinRT applications are run in secure sandboxes, with limited access to the rest of the system, and they can be suspended or terminated at any time, with only limited support for multitasking.
These factors all influence the design of the WinRT API: in Windows 8, the first iteration of WinRT, it's not a general purpose API, and it's not supposed to be. Much of the API is unexceptional and will feel reasonably familiar to Windows and .NET developers, but a couple of parts deserve special attention: the features it has for GUIs and the general approach to both disk and network I/O.
Once again, Microsoft looked at the technologies it had already developed and reinvented them for WinRT's GUI API. WinRT borrows heavily from WPF and Silverlight. It uses a new dialect of XAML, the same XML-based markup language for GUI design, and uses essentially the same techniques for plumbing application data into the GUI, and responding to user input. There is an arguably important difference, however: WinRT's XAML toolkit is written in native code, whereas all the XAML toolkits that went before it (WPF, Silverlight, and Windows Phone—the three are, regrettably, similar, but not entirely compatible) were predominantly written in .NET code.
Though WPF itself was managed code, it had an important native code part to handle actual drawing to screen. That's because it used Direct3D for drawing, to enable it to take advantage of hardware acceleration. Realizing that that native code portion was generally useful, Microsoft refined it to create Direct2D, a hardware-accelerated API for 2D applications. However, WPF was never switched to use Direct2D; it still uses its own, private library. WinRT's XAML, however, does use Direct2D.
This is a logical evolution. However, the decision to rewrite the XAML stack in native code has come at some cost; WinRT XAML lacks many of the capabilities of WPF, and even Silverlight, its closest relative, provides a richer, more capable library than WinRT right now. This is not to say that WinRT is weaker than Silverlight across the board—its media and image handling capabilities are better than those of Silverlight, for example—but as a GUI toolkit, it's a small step backwards for Silverlight developers and a large one for WPF users.
Keeping the user interface fast and fluid
As is the case with every mainstream GUI library, WinRT's XAML is single-threaded. On the face of it, this might seem an odd decision, given today's proliferation of multicore, multithreaded processors, but it isn't. By "single-threaded" I mean that user input is all delivered on a single thread, and updates to the UI must all be made on that same single thread. This is because these things have a clear ordering to them: if I type 'c' 'a' 't' on the keyboard, it's imperative that the application sees those keystrokes in that order and handles them sequentially. If user input were delivered on multiple threads, it would be possible for input that was generated later to be processed sooner.
Microsoft's News app was shown off in 2011 when Windows 8 was revealed.
This single-threaded approach has a well-known downside, however. If the thread handling input ever pauses for some reason, it means that the application can't handle any other input. The input just gets queued up. If the thread pauses for long enough, that queue can fill up completely, at which point Windows will beep each time you try to add new input (by pressing the mouse button or typing), and the new input events are simply discarded.
To avoid this problem, then, you have to make sure that the input thread never pauses. Unfortunately, while most developers know that they're not supposed to make their input thread block, they often do it anyway. It's just too easy to do. The traditional culprits are I/O—either doing something with the disk, or with the network. The thing about I/O is that it can be really slow. A network connection to an unavailable server can wait several seconds before failing, for example. Attempt this connection in your input thread, and you'll end up blocking input for several seconds, creating an application that's unresponsive and slow.
In spite of knowing about this problem, developers continue to attempt I/O from the input thread. Part of the reason is that it's insidious. Imagine an application that communicates with some network server. In development and testing, that server could be local to the developer; perhaps on the developer's own machine, or at least on his own LAN. In this situation, the network connections will always seem to be fast enough that they're safe to perform in the UI thread. They may still take a few milliseconds, but the delay probably won't be noticed, so it's easy for the developer to think it's good enough. It's only when the application is used in the real world that the problem emerges: the real world has crappy hotel Wi-Fi and slow 3G connections where each network connection can introduce hundreds or thousands of milliseconds of delay. All of a sudden, the application that was fast and fluid for the developer is slow and jerky for the user.
Part of the reason that developers do this is that it's just plain easier. Many I/O APIs are exclusivelysynchronous and blocking, which is to say, that they make the thread calling the API stop in its tracks while waiting for the I/O operation to occur ("synchronous" and "blocking" are often used synonymously; though there are subtleties that make this not quite accurate, it's probably good enough for our purposes). Many more I/O APIs are synchronous and blocking by default, but also offer non-default modes that are asynchronous and non-blocking; that is, they allow the thread calling the API to keep on working even while the I/O operation is occurring in the background.
The reason that synchronous APIs are so often the default is that they're much easier to work with and think about. A lot of what programs have to do is sequential in nature. You can't read a file until you've first opened it, and you can't interpret the data until you've first read it from the file. Necessarily, when the user clicks a button to load a file, you have to open the file, then read the file, and then interpret the data. Synchronous APIs, where the thread stops what it's doing until the file is opened, and then stops again until the data has been read, make this sequential programming natural and easy.
Asynchronous APIs aren't so straightforward. The virtue of an asynchronous API is that the thread that started the I/O operation can do something else while it's waiting for the I/O to finish. The difficulty with an asynchronous API is figuring out just what to do once the I/O operation is done, and the data is available, ready to be used. The thread that started the I/O operation has moved on with its life and is now busy responding to the next bit of user input; as far as that thread is concerned, the fact that the user clicked a button to load a file has been dealt with.
Providing a neat way for the programmer to specify what happens next is one of the biggest challenges for asynchronous APIs. They all need a way of letting the developer say "once the data has been read, then do this;" turning the sequential ordering that's implicit with synchronous APIs and making it explicit.
The approaches that asynchronous APIs use to handle this vary. Windows has always had asynchronous APIs. The Windows jargon is "Overlapped I/O," because you can perform multiple I/O operations on a file simultaneously, such that the operations overlap with one another. The way in which it handled this particular issue was very primitive and low-level. The operating system would tell the application when each overlapped operation was complete, but it was entirely up to the application to work out which I/O operation is which, and what the next processing step is.
Awkward as it may seem, way back in the OS/2 days Windows was originally designed to work this way exclusively, and behind the scenes, all I/O is overlapped I/O. But because it's so awkward to use, the kernel team added the ability to have the kernel take care of the asynchrony and act as if it had synchronous APIs.
Traditional UNIX systems have had a vaguely similar approach for network I/O—the system would tell you which operation was done and the application would then determine how to proceed—but unlike Windows offered nothing comparable for file operations. Modern UNIX systems use a variety of (incompatible) mechanisms for handling asynchronous disk and network I/O (though again, this tends to be quite low level), and some also support standard POSIX asynchronous I/O (AIO). POSIX AIO is notable because it has two modes of operation. It can work similarly to the other APIs, merely informing an application that an I/O operation is complete, but it has a second mode: the application can specify a particular function to call when an I/O operation is complete, and the operating system will call that function directly when it's the right time to do so. This kind of function, a function in theapplication's code that the operating system calls is known as a "callback."
Not everything that can hold up the input thread is an I/O operation, of course. Sometimes computation itself is the slow part. So as well as a way of doing I/O asynchronously, there needs to be a way of doing computations asynchronously; of pawning them off onto a separate thread, so that the input thread can keep on trucking. Over the years, many ways of doing this have developed. The time-honored UNIX approach was to use a separate process for each separate computation. In Windows, the preference has been to create separate threads for these background tasks.
There's also a converse problem. Updating the UI is also single-threaded, and it has to be done from the input thread. This means that there needs to be a way of switching back to the input thread to make changes to the user interface, after any I/O (or slow computation) has been performed.
WinRT's approach: asynchronous I/O...
WinRT addresses the "don't block the input thread" issue by making its I/O APIs asynchronous. Dogmatically so. They're all asynchronous, all the time, for both disk and network I/O (though some of the Win32 APIs that Metro applications are permitted to use remain synchronous). Each asynchronous operation can have a callback specified, and the callback will be run whenever the operation is complete. WinRT has a set of four standard interfaces that are used by all asynchronous operations, and another set of interfaces for the callbacks themselves.
Even though callbacks are arguably the most straightforward way of using this kind of API, it's still harder work for developers than a synchronous API. To improve this situation somewhat, Microsoft added some new features to the C# and Visual Basic.NET languages for handling asynchronous APIs. With these extensions—an
async keyword used to turn a regular function into an asynchronous one, and an await keyword, to indicate that the program needs to wait for an asynchronous operation to complete—developers can write programs that have the same sequential appearance as synchronous APIs, but which get converted by the compiler into the right mix of callbacks. Superficially, this provides much of the ease of use of synchronous APIs, though the details are complex. Even Microsoft's own sample code has included bugs as a result of improper use of asyncand await; while it may look like synchronous code, it isn't.
For C++ programmers, there are no new keywords, but Microsoft is shipping a library called the Parallel Patterns Library (PPL). This covers up most of the details by allowing plain C++ functions to be used as callbacks, rather than forcing developers to deal with the special WinRT interfaces directly.
On the one hand, it's easy to see why Microsoft has gone this all-asynchronous route. Though developers can subvert the system in various ways to make it act synchronously, there's a much greater chance that they'll do the Right Thing and use the asynchronous API asynchronously, and as a result, the input thread is much less likely to get tied up. The net result should be applications that are much better at staying responsive—the whole "fast and fluid" thing.
On the other hand, asynchronous APIs are harder to use than synchronous ones, with more subtle complexities. They also tend to make debugging harder. Asynchronous APIs are one solution to not blocking the input thread, and that's valuable, but they're far from the only solution. Calling synchronous APIs on a background thread achieves the same thing, but without most of the additional complexity. The asynchronous APIs also make porting existing code from other platforms (including legacy Windows code) harder than it needs to be.
... and thread pools
For non-I/O tasks, WinRT eschews the traditional Windows solution of threads. In fact, WinRT offers no API for creating a thread at all. WinRT programs are still multithreaded, but the operating system, rather than the application, has responsibility for managing those threads. What it does offer instead are thread pools. Thread pools are groups of system-managed threads that sit around waiting to be given some work. When an application wants to do some processing in the background, it assigns the piece of work to the thread pool. The pool picks one of its threads at random, uses it to perform the work. When it's finished, the thread goes back to sleep, waiting for the next item.
This design decision is a little strange. It makes porting any existing applications more than a little awkward, as most existing applications expect to create their own threads on an as-needed basis (though Microsoft developers have produced a library that implements the old Windows threading API on top of the WinRT thread pool API to ease this migration), and it's extremely poorly documented, giving no indication of what happens if, for example, more work is given to the thread pool than the pool has threads available (it probably adds more threads, but the policy it uses for doing so matters; if it doesn't add enough threads, it can break applications).
As with the asynchronous decision, the threading approach is certainly different from what went before. It's just not altogether clear that it's better. Some things are easier; others aren't.
Sandboxing and the app model
There are many things possible in Win32 that aren't possible in WinRT. The biggest single reason for these omissions are due to the application and security model that WinRT applications use. Win32 is an application free-for-all. Though there are, of course, restrictions based on user identities, file permissions, and firewalling, a Win32 application, especially one running as an Administrator, can do pretty much whatever it likes. There are good sides to this—useful utilities can extend Explorer, Web browsers can save files anywhere, applications can support plug-ins and extensions, programs can run persistently in the background to respond to network events or hotkeys. But there are also bad sides to it—applications can overwrite each other's files, or hijack the Web browser, or spy on keystrokes, or chew through processor cycles and battery life even when running in the background.
The WinRT application model is far more constrained than the Win32 environment of old. WinRT applications will be constrained to sandboxes. They will be isolated both from each other and the operating system: WinRT applications won't in general be allowed to communicate each other, whether for good reasons (such as plug-ins) or bad (such as spyware). They will have only limited access to the file system: by default, they will only be able to open or save files that the user has explicitly picked. Applications generally won't be able to run persistently: the system reserves the right to suspend or kill any application in the background.
And WinRT applications will run (or rather, not run) in the background a lot. WinRT applications will run in one of two ways: full-screen, or in an asymmetric split side-by-side view, when one application has the majority of the screen and the other has a thin strip at the side. Any application not visible is in the background and hence suspended and eligible for termination.
The full mechanics of the sandbox mechanism are beyond the scope of this brief introduction to WinRT, and in principle, the sandbox system is an operating system feature that isn't specifically tied to WinRT. However, it does have a variety of implications for the WinRT API.
Chief among them is that WinRT has no mechanisms for interprocess communication (IPC). Normal Windows applications can communicate between one another in all sorts of ways; they can send messages between one another to simulate mouse and keyboard input (and more), they can use the clipboard, they can create local network connections, they can share pieces of memory, they can use certain COM-related technologies; there are lots of options. The problem with all of these systems is that they tend to be quite susceptible to various kinds of attack, and as such, all of them are off-limits to WinRT applications, except for the clipboard, for which there's some support.
This is all nice for security and isolation, but applications that can't communicate with one another at all are far from ideal. We want to be able to do things like open a photo in a photo app and then send that to Twitter, or Facebook, or attach it to an e-mail. For these kind of communication tasks WinRT has a number of related, structured communication channels that Microsoft has called contracts andextensions. Contracts are for things like sharing data; they're channels for applications to communicate with each other. Extensions are for applications to communicate with the operating system itself, and are used for things like handling specific file types and protocols, or providing camera effects.
Even with contracts, there's no direct communication between applications. It's all orchestrated by system components that pass the necessary data between applications, either directly or via files on disk. Applications have to declare which contracts they support, if any, and the operating system performs the necessary filtering required. For example, if the current app is offering up a piece of text to share, only those apps that declare that they are able to receive shared text will be made available.
In this way, the contracts retain the strict isolation between applications and protect them from the free-for-all that traditional Windows IPC implies.
There is, however, a substantial downside to the contracts. As is this case with most of WinRT, contracts aren't usable in desktop applications. This means that, for example, a desktop e-mail client such as Outlook can't be used as a share target. Opening up these contracts to desktop applications would require a bit more plumbing on Microsoft's part, but would greatly enhance the experience of using a mix of WinRT and non-WinRT applications.
An evolutionary revolution
WinRT is a curious beast. It brings together some of Microsoft's oldest ideas—including COM and asynchronous I/O everywhere—and combines them with some of Microsoft's newest ideas, such as XAML and Direct2D. Microsoft positions it as being a kind of new Windows subsystem, disconnected from the Win32 legacy, but it turns out to be just a nicer way of using the same old Win32 APIs that have been evolving for two decades now. It could be the future of Windows application development, but it doesn't have to be. If it fails to attract developer and user interest, it could be sidelined or repositioned, perhaps by breaking down the wall between desktop apps and Metro apps and offering the same set of APIs to each.
In a sense, WinRT is much closer to something like MFC and .NET than Microsoft's diagram and promotion lets on. MFC ("Microsoft Foundation Classes") is a library that the company has offered C++ developers since the early 1990s that provides a set of classes built on top of Win32 that makes Win32 somewhat less painful to use and more "object oriented." Fundamentally, WinRT, MFC, and .NET are all layers on top of Win32 (rather than replacements for Win32) that provide a "modern" development environment. The exact meaning of "modern" has changed over the years to accommodate different coding styles and practices, and .NET and MFC have some advantages that WinRT doesn't (for example, much of their source code is published, making it much easier to figure out what's going on behind the scenes and why things aren't working), but the goal of all three has been the same: to make it easier to write software for Windows.
Microsoft is taking a risk with WinRT, as developers may not follow it, but it's a calculated risk, and it's a low risk. The re-use and modernization of existing technology gives WinRT instant familiarity for developers, but also an easy path for Microsoft to extend the reach and capabilities (and ease the restrictions) should it need to. It's at once the embodiment of Windows' future and the embracing of Windows' past.
It is really a nice and helpful piece of info. I'm happy that you shared thiss helpful info with us.
ReplyDeletePlease stay us informed like this. Thanks for sharing.
Alsoo visit my homepage - microsoft office 2010 keygen