
Bandwidth—the number of bits per second that a device or connection can transfer every second—is the number that everyone loves to talk about. Whether it be the gigabit per second that your Ethernet card does, boasting about your fancy new FTTP Internet connection at 85 megabits per second, or bemoaning the lousy 128 kilobits per second you get on hotel Wi-Fi, bandwidth gets the headlines.
Bandwidth isn't, however, the only number that's important when it comes to network performance. Latency—the time it takes the message you send to arrive at the other end—is also critically important. Depending on what you're trying to do, high latency can make your network connections crawl, even if your bandwidth is abundant.
Why latency matters
It's easy to understand why bandwidth is important. If a YouTube stream has a bitrate of 1Mb/s, it's obvious that to play it back in real time, without buffering, you'll need at least 1Mb/s of bandwidth. If the game you're installing from Steam is about 3.6GB and your bandwidth is about 8Mb/s, it will take about an hour to download.
Latency issues can be a bit subtler. Some are immediately obvious; others are less so.
Nowadays, almost all international phone calls are typically placed over undersea cables, but not too long ago, satellite routing was common. Anyone who's used one or seen one on TV will know that the experience is rather odd. Conversation takes on a disjointed character because of the noticeable delay between saying something and getting acknowledgement or a response from the person you're talking to. Free-flowing conversation is impossible. That's latency at work.
There are some applications, such as voice and video chatting, which suffer in exactly the same way as satellite calls of old. The time delay is directly observable, and it disrupts the conversation.
However, this isn't the only way in which latency can make its presence felt; it's merely the most obvious. Just as we acknowledge what someone is telling us in conversation (with the occasional nod of the head, "uh huh," "go on," and similar utterances), most Internet protocols have a similar system of acknowledgement. They don't send a continuous never-ending stream of bytes. Instead, they send a series of discrete packets. When you download a big file from a Web server, for example, the server doesn't simply barrage you with an unending stream of bytes as fast as it can. Instead, it sends a packet of perhaps a few thousand bytes at a time, then waits to hear back that they were received correctly. It doesn't send the next packet until it has received this acknowledgement.
Because of this two-way communication, latency can have a significant impact on a connection's throughput. All the bandwidth in the world doesn't help you if you're not actually sending any data because you're still waiting to hear back if the last bit of data you sent has arrived.
How latency works
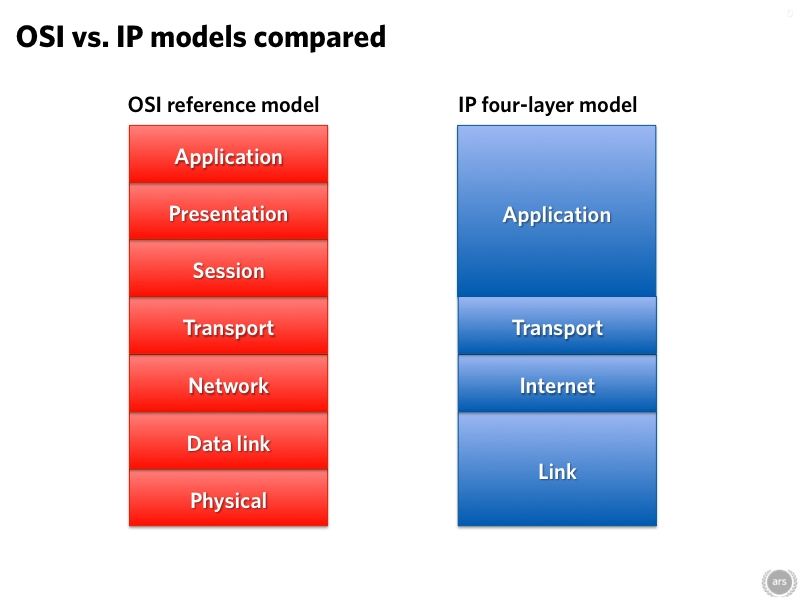
It's traditional to examine networks using a layered model that separates different aspects of the network (the physical connection, the basic addressing and routing, the application protocol) and analyze them separately. There are two models in wide use, a 7-layered one called the OSI model and a 4-layered one used by IP, the Internet Protocol. IP's 4-layer model is what we're going to talk about here. It's a simpler model, and for most purposes, it's just as good.
Sometimes c just isn't enough
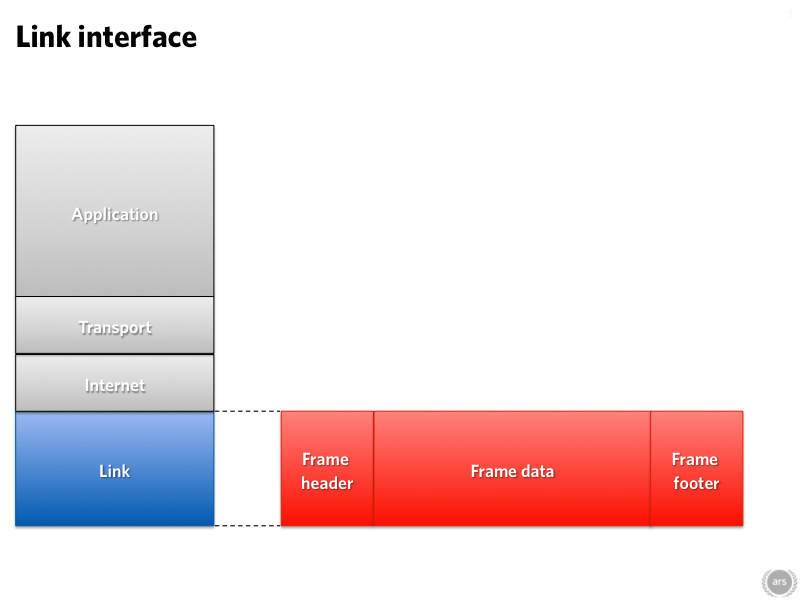
The bottom layer is called the link layer. This is the layer that provides local physical connectivity; this is where you have Ethernet, Wi-Fi, dial-up, or satellite connectivity, for example. This is the layer where we get bitten by an inconvenient fact of the universe: the speed of light is finite.
Take those satellite phones, for example. Communications satellites are in geostationary orbits, putting them about 35,786 kilometers above the equator. Even if the satellite is directly overhead, a signal is going to have to travel 71,572 km—35,786 km up, 35,786 km down. If you're not on the equator, directly under the satellite, the distance is even greater. Even at light speed that's going to take 0.24 seconds; every message you send over the satellite link will arrive a quarter of a second later. The reply to the message will take another quarter of a second, for a total round trip time of half a second.
Undersea cables are a whole lot shorter. While light travels slower in glass than it does in air, the result is a considerable improvement. The TAT-14 cable between the US and Europe has a totalround trip length of about 15,428 km—barely more than a fifth the distance that a satellite connection has to go. Using undersea cables like TAT-14, the round trip time between London and New York can be brought down below 100 milliseconds, reaching about 60 milliseconds on the fastest links. The speed of light means that there's a minimum bound of about 45 milliseconds between the cities.
The link layer can have impact closer to home, too. Many of us use Wi-Fi on our networks. The airwaves are a shared medium: if one system is transmitting on a particular frequency, no other system nearby can use the same frequency. Sometimes two systems will start broadcasting simultaneously anyway. When this happens, they have to stop broadcasting and wait a random amount of time for a quiet period before trying again. Wired Ethernet can have similar collisions, though the modern prevalence of switches (replacing the hubs of old) has tended to make them less common.
The Internet is an internetwork
The link layer is the part that moves traffic around the local network. There are usually lots of links involved in using the Internet. For example, you might have home Wi-Fi and copper Ethernet to your modem, VDSL to a cabinet in the street, optical MPLS to an ISP, and then who knows. If you're unlucky, you might even have some satellite action in there. How does the data know where to go? That's all governed by the next layer up: the internet layer. This links the disparate hardware into a singular large internetwork.
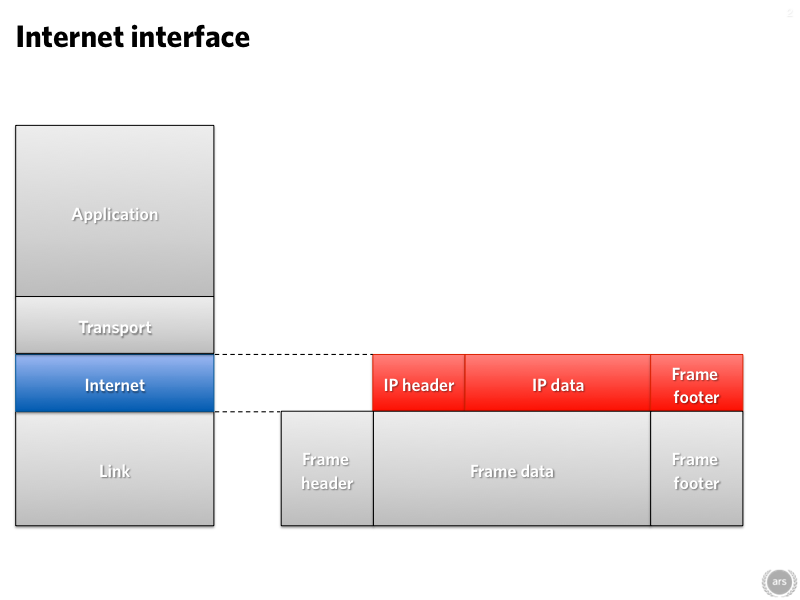
The internet layer offers plenty of scope for injection of latency all of its own—and this isn't just a few milliseconds here and there for signals to move around the world. You can get seconds of latency without the packets of data going anywhere.
The culprit here is Moore's Law, the rule of thumb stating that transistor density doubles every 18 months or so. This doubling has the consequence that RAM halves in price—or becomes twice as large—every 18 months. While RAM was once a precious commodity, today it's dirt cheap. As a result, systems that once had just a few kilobytes of RAM are now blessed with copious megabytes.
Normally, this is a good thing. Sometimes, however, it's disastrous. A widespread problem with IP networks tends more to the disastrous end of the spectrum: bufferbloat.
Network traffic tends to be bursty. Click a link on a webpage and you'll do lots of traffic as your browser fetches the new page from the server, but then the connection will be idle for a while as you read the new page. Network infrastructure—routers, network cards, that kind of thing—all has to have a certain amount of buffering to temporarily hold packets before transmitting them to handle this bursty behavior and smooth over some of the peaks. The difficult part is getting those buffers the right size. A lot of the time, they're far, far too big.
That sounds counter-intuitive, since normally when it comes to memory, bigger means better. As a general rule, the network connection you have locally, whether wired or wireless, is a lot faster than your connection to the wider Internet. It's not too unusual to have gigabit local networking with just a megabit upstream bandwidth to the 'Net, a ratio of 1,000:1.
Thanks again to Moore's Law (making it ridiculously cheap to throw in some extra RAM), the DSL modem/router that joins the two networks might have several megabytes of buffer in it. Even a megabyte of buffer is a problem. Imagine you're uploading a 20MB video to YouTube, for example. A megabyte of buffer will fill in about eight milliseconds, because it's on the fast gigabit connection. But a megabyte of buffer will take eight seconds to actually upload to YouTube.
If the only traffic you cared about was your YouTube connection, this wouldn't be a big deal. But it normally isn't. Normally you'll leave that tediously slow upload to churn away in one tab while continuing to look at cat pictures in another tab. Here's where the problem bites you: each request you send for a new cat picture will get in the same buffer, at the back. It will have to wait for the megabyte of traffic in front of it to be uploaded before it can finally get onto the Internet and retrieve the latest Maru. Which means it has to wait eight seconds. Eight seconds in which your browser can do nothing bit twiddle its thumbs.
Eight seconds to load a webpage is bad; it's an utter disaster when you're trying to transmit VoIP voice traffic or Skype video.
The TCP in TCP/IP
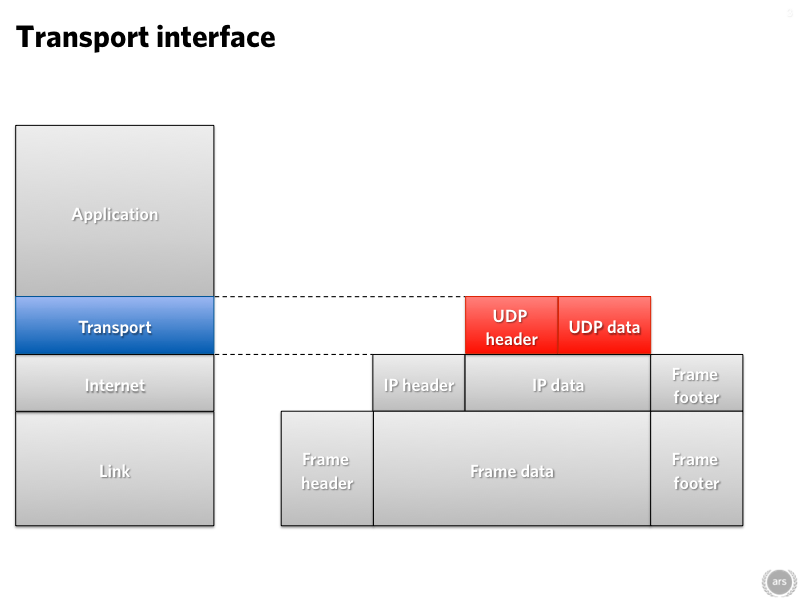
Moving up another layer, we have the transport layer. The transport layer is in many regards a convenience layer, providing useful services to applications to help them use the network more easily. The most common transport layer protocol is TCP, Transmission Control Protocol. It's so important that it's normally named alongside IP ("TCP/IP"), though IP can carry more than just TCP.
TCP is so useful because it allows programmers to treat the network not as a series of packets but as a continuous, reliable stream of bytes. TCP has lots of built-in features. For example, if two packets arrive in a different order than they were sent, TCP reorganizes them so that they're chronological. If a packet gets lost somewhere along the way, TCP will ensure it gets retransmitted.
The other big protocol layered over IP is UDP, User Datagram Protocol. UDP is dumb as a box of rocks. It doesn't do anything to disguise IP's packet based design or make it any more convenient. It doesn't care if packets arrive in order or not. It doesn't care if packets arrive at all. A sending application can just spew out UDP packets as fast as it likes, and the receiving application can handle them as fast as it can. But if anything gets lost along the way, too bad, so sad. UDP still has to contend with bufferbloat and the speed of light, but it doesn't really add any latency of its own. It's too stupid for that.
TCP is another matter. TCP's reliable delivery is the reason why, just like our satellite conversation with its "uh huhs" and "yeahs," TCP requires a continuous stream of acknowledgements to tell the sender that each packet has been received successfully. Those acknowledgements in turn make TCP very sensitive to latency.
With simple protocols like UDP, the throughput (that is, the rate of successful transfers over the communication medium) tends to be limited only by the bandwidth. With TCP, that all stops: a TCP network can have throughput that's lower than the bandwidth, with the limit caused by latency.
TCP's designers were no idiots, however, and so the protocol is designed with a number of features to adapt to latency. TCP stacks try to estimate the bandwidth-delay product. This is a measure of the amount of data that can be in-flight, over the network, at any one time; it's a product of the bandwidth and the round trip latency. TCP endeavors to send this amount of data between acknowledgements.
However, there are limits to this. Consider satellite again. A satellite connection could have a relatively high bandwidth of 1.5Mb/s (188kB/s), but its latency will still be around 0.5 s. IP packets can be as long as 216 bytes, 65kB. A TCP connection will send that 65kB and then wait for a reply, which will come half a second later. The total throughput, then, will be 130kB per second. That's not awful—but it's quite a way short of the 188kB/s that the connection can actually sustain.
TCP has a way to handle that, too; an option was added in 1992 that allows the amount of data in flight to be larger than 65kB. Allow that satellite link to have 94kB in flight at a time, and the throughput will start matching the bandwidth again. Historically, there were still systems on the Internet that didn't support this option, which would break the connections. Fortunately, this is pretty rare these days—it was added to Windows in Windows 2000, and to Linux in 2004.
Sometimes, however, TCP's efforts to increase throughput can make the latency worse in undesirable ways. Because each IP packet and TCP packet has some overhead (20 bytes each, for 40 bytes of total overhead), TCP tries not to send really small packets containing just a few bytes. That's because in such transfers, the overhead of the packet overwhelms the actual data: 40 bytes of overhead for just a byte or two of actual data. To combat this inefficiency, TCP tries to aggregate small transfers, delaying them a little to improve the ratio of data to overhead. This is called Nagle's algorithm.
That can be good for throughput, but bad for latency. Some network protocols, such as the venerable telnet protocol and its modern successor, ssh, have extremely low data rates. They typically run at the speed of a person typing on a keyboard. Just a few bytes per second. Nagle's algorithm is a bad fit for this kind of protocol, as it prevents each keystroke from being sent as soon as it's typed. The result is much higher latency, and latency that's particularly noticeable, because it's inflicted on a highly interactive protocol: a protocol where users expect to press a key and see the result on-screen "immediately," not half a second later. Fortunately, TCP allows Nagle's algorithm to be disabled, to make TCP a better fit for this kind of protocol.
Putting it all to use

The final layer in the stack is the application layer. This is the layer that includes protocols like the Web's HTTP. Unsurprisingly, there's plenty of scope for latency to cause problems here. A fine example is the SMB (also known as CIFS) protocol used for Microsoft's file sharing since the 1990s. SMB is by nature a chatty protocol: a client opening a file on a server doesn't require one round trip from the client to the server. It requires several.
This is fine on a LAN, where each round trip takes a millisecond or less. It's completely less than fine when you're trying to access your corporate file server remotely over a VPN, where each round trip takes 100 milliseconds. A few round trips to list a directory in Explorer and then double-click a file to open it and you're adding seconds of latency.
HTTP has issues like this too. A Web client first fetches the page from a server. One round trip. The page then lists images, CSS stylesheets, JavaScript files, and maybe more. The client then has to fetch each of those from a server—one round trip for each file. HTTP can make multiple connections to a server to allow files to be downloaded in parallel, but traditionally this has been limited to two or four connections per server. Apart from that limited parallelism, the client has to fetch the files one by one, sequentially, having to wait for a round trip each time. The result is that the time it takes to load a webpage is often dominated by latency.
There are also lots of other small sources of latency sneaking in here and there. For example, at the internet layer, there's the fact that routers aren't quite instantaneous. Buffering considerations aside, it takes a finite amount of time for a router to read an IP packet and figure out where it's meant to go. The process is very quick, but it's not instant. At the link layer, Ethernet has to leave a tiny gap between transmissions, so sending a message can be delayed momentarily for that. Undersea optical cables have to include periodic repeaters to boost the signal. These add small delays. At the application layer, applications themselves add delays: a Web server, for example, might have to spend 10 milliseconds retrieving a requested file from disk before it can respond.
As long as things are working normally, most of these additional sources of latency (except the application) add only an imperceptible delay. Occasionally that's not the case. Modern routers typically implement some kind of "fast path" for "normal" traffic that reduces the work the router has to do and improves performance. Traffic that can't use that fast path because it needs some more complex handling (such as breaking up a large packet into a series of smaller ones) can get bogged down.
These different latency sources all conspire to work together. Link layer latency means that long distance connections are going to have a certain amount of unavoidable slowness. Bufferbloat can make that latency substantially worse, and TCP connections will merrily fill those buffers if they think that the bandwidth-delay product is high enough. To top it all off, protocols like HTTP mean that you suffer not just one round trip's worth of latency, but many. The result? Interactive protocols can lose their responsiveness, and throughput can fall far short of available bandwidth.
What can you do about it?
Fortunately, there are some things we can do about latency. But let's start with the bad news first. Sadly, scientists haven't bothered to do anything to make the speed of light faster. It seems we're pretty much stuck with that one. A European playing on an American server for the first person shooter du jour is always going to be on the wrong end of 80 to 100 milliseconds of latency. That's just the way it is. For some applications, this will always have an impact on the way people use the service: using VoIP to talk to someone on the other side of the world will never be quite like talking to them in person, because the latency will always get in the way.
The good news is that we do, however, have some control over the other layers. After first being recognized in 1985 by John Nagle (of Nagle's Algorithm fame), the bufferbloat problem has, in the last couple of years, finally gained the attention of people building network hardware and software. The DOCSIS specification that defines how cable modems work and interoperate was updated to allow manufacturers to use smaller buffers in their modems, reducing the bloat.
On the software side, traffic shaping algorithms can provide some relief. Rather than using a single large buffer for all IP traffic, traffic shaping systems can buffer different kinds of traffic separately and prioritize them to make sure to send, say, VoIP traffic out before Web traffic. The development ofmore complex systems that detect a problem and tell connections (particularly TCP connections) to slow down before buffers get filled up is also an area of active study.
Smarter protocols at the application layer help too. HTTP has an option called pipelining. With pipelining, a Web browser can request several files from a server back-to-back without having to wait for each response. This means that instead of having to wait for one round trip per request, the client only has to wait for one round trip for the whole lot. Pipelining has been part of the HTTP specification since 1999, but only within the past few years has it achieved widespread adoption in browsers.
This is a fairly general technique. Google's HTTP alternative, SPDY, uses pipelining. So does SMB2, the new version of Microsoft's file sharing protocol that was first used in Windows Vista.
But perhaps the most significant saving is using the higher layers to tackle the link layer problem. It may not be possible to make light go any faster, but it's sometimes possible to make the distance a lot shorter. This is almost as good.
For example, Microsoft has two features, one called BranchCache, the other Offline files, that both provide local caching of SMB shares. With Offline files, a system that provides a local cache of network files, the remote worker might not have to send network requests over his slow VPN on his slow hotel Wi-Fi and suffer the misery of a chatty protocol on a high latency network. BranchCache serves a similar role, but it's designed to serve an entire branch office, to prevent users from having to hit the main office's servers and instead load files from the local network. These systems use modifications of the application layer and operating system to do their thing.
A broadly similar technique is used to cut Web serving latencies. Content Delivery Networks (CDNs) replicate Web content—usually static stuff like images and scripts—to datacenters scattered around the globe. Networking trickery at the internet layer is used to transparently direct browsers to whichever data center is nearest to them, and hence has the lowest latency. This in turn makes all those round trips quicker, so webpages load faster.
These are all simply lessening the blow. None of these tricks make latency go away. And the truth of it is: until scientists invent subspace communications, they never will.
No comments:
Post a Comment
Let us know your Thoughts and ideas!
Your comment will be deleted if you
Spam , Adv. Or use of bad language!
Try not to! And thank for visiting and for the comment
Keep visiting and spread and share our post !!
Sharing is a kind way of caring!! Thanks again!